Azure VMware Solution управляет глобальным парком производственных приватных облаков, каждое из которых работает в полноценной управляющей плоскости (control plane) VMware NSX и vCenter Server. Когда, например, кластер VMware NSX Manager теряет кворум, NSX может генерировать множество связанных алармов, однако наблюдаемое воздействие выглядит как одновременный каскадный сбой: обновления плоскости управления и конфигурации прекращаются, работоспособность кластера может деградировать, а некоторые симптомы Edge-узлов или транспортных узлов могут проявляться следом — при этом существующая динамическая маршрутизация Tier-0, как правило, остаётся работоспособной. Иными словами, несколько симптомов могут иметь один общий корневой сбой, который необходимо верифицировать с учётом состояния кластера, работоспособности сервисов, хранилища, состояния Compute Manager и связности транспортных узлов. Без модели, кодирующей направленные зависимости между этими уровнями, набор тревог структурно неотличим от множества независимых одновременных сбоев.
Оператор, обрабатывающий каждую тревогу независимо, продлевает инцидент, повторно проходя один и тот же путь распространения сбоя с каждым действием. В условиях производственных масштабов распространение сбоев NSX стабильно опережает ручную сортировку инцидентов. Система автономного самовосстановления приватного облака Azure VMware Solution — это архитектура управления с замкнутым контуром, созданная для устранения именно этого класса сбоев. Система коррелирует сигналы плоскости управления причинно-следственным образом с использованием динамического графа зависимостей в реальном времени, применяет полный стек политик-шлюзов перед любым автоматическим действием, захватывает ограниченное взаимное исключение перед началом выполнения и независимо верифицирует восстановление прежде, чем закрыть инцидент. В данной статье описываются архитектура системы и принятые проектные решения.
Архитектурные компоненты
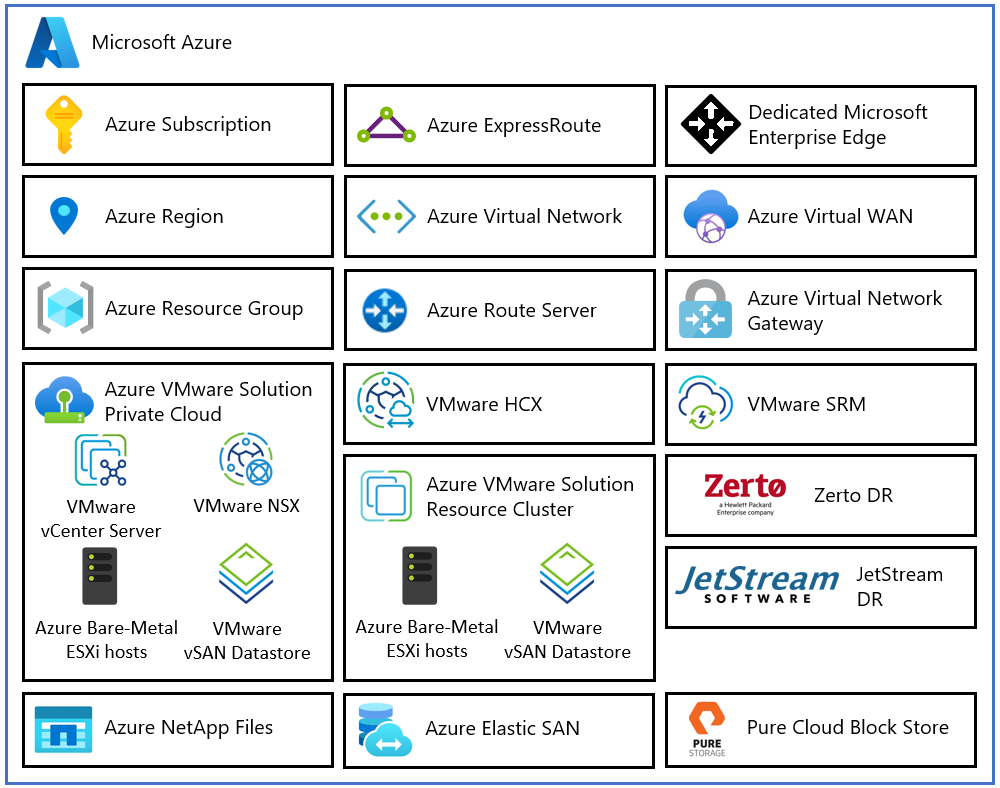
Azure VMware Solution — это VMware-валидированный сервис Azure первой стороны от Microsoft, предоставляющий приватные облака с кластерами VMware vSphere на базе выделенной bare-metal инфраструктуры Azure. Это позволяет заказчикам использовать существующие инвестиции в навыки и инструменты VMware, сосредоточившись на разработке и запуске своих VMware-нагрузок в Azure.
Каждый архитектурный компонент Azure VMware Solution выполняет следующие функции:
Azure Subscription — управление доступом, бюджетом и квотами для Azure VMware Solution.
Azure Region — физические местоположения по всему миру, объединяющие центры обработки данных в зоны доступности (AZ), а зоны доступности — в регионы.
Azure Resource Group — контейнер для группировки сервисов и ресурсов Azure в логические группы.
Azure VMware Solution Private Cloud — использует программное обеспечение VMware, включая vCenter Server, программно-определяемые сети NSX, программно-определяемое хранилище vSAN и bare-metal хосты ESXi Azure для предоставления вычислительных ресурсов, сетевых ресурсов и хранилища. Поддерживаются также Azure NetApp Files, Azure Elastic SAN и Pure Cloud Block Store.
Azure VMware Solution Resource Cluster — масштабирует приватное облако за счёт дополнительных bare-metal хостов ESXi и программного обеспечения vSAN.
VMware HCX — обеспечивает мобильность, миграцию и расширение сети.
VMware Site Recovery — обеспечивает автоматизацию аварийного восстановления и репликацию хранилища через vSphere Replication. Также поддерживаются сторонние решения DR — Zerto DR и JetStream DR.
Dedicated Microsoft Enterprise Edge (D-MSEE) — маршрутизатор, обеспечивающий связность между Azure и приватным облаком Azure VMware Solution.
Azure Virtual Network (VNet) — частная сеть для соединения сервисов и ресурсов Azure.
Azure Route Server — позволяет сетевым устройствам обмениваться динамической информацией о маршрутизации с сетями Azure.
Azure Virtual Network Gateway — кросс-облачный шлюз для подключения через IPSec VPN, ExpressRoute и VNet-to-VNet.
Azure ExpressRoute — высокоскоростные приватные подключения между центрами обработки данных Azure и локальной или колокационной инфраструктурой.
Azure Virtual WAN (vWAN) — объединяет функции сетевого взаимодействия, безопасности и маршрутизации в единую глобальную сеть.
Что обеспечивает автономное самовосстановление
Система автономного самовосстановления вводит пять гарантированных на системном уровне свойств корректности, ни одно из которых ранее не существовало как системно-принудительное поведение в пути реагирования на инциденты плоскости управления Azure VMware Solution:
Возможность
Что делает Autonomous Self-Heal
Предыдущее состояние
Ограниченное, верифицируемое время восстановления
Измеряет время от первого скоррелированного сигнала до верифицированного стабильного восстановления.
Инциденты закрывались по завершении действия, а не восстановления.
Целостность сигнала при поступлении
Нормализует события, дедуплицирует источники и подавляет флаппинг перед корреляцией.
Конвейера нормализации не существовало. Инженеры получали необработанный поток тревог.
Выполнение с политикой-шлюзом
Атомарно проверяет окна заморозки, бюджеты риска, радиус проблемы, ограничения скорости и согласования перед выполнением.
Единого атомарного стека шлюзов для ограничений и согласований не существовало.
Доказательная база инцидента с возможностью только дополнения
Сохраняет сигналы, топологию, решения, трассировку workflow и верификацию в структурированной записи.
Доказательства находились в отдельных журналах и с трудом воспроизводились.
Прогрессивная модель доверия
Поддерживает режим только-уведомления, чтобы операторы могли проверить обнаружения и предлагаемые действия перед включением.
Автоматизация была бинарной — не было механизма наблюдения за поведением системы до предоставления полномочий на выполнение.
Принципы проектирования
Автономное самовосстановление вводит семь проектных элементов в операции плоскости управления приватным облаком Azure VMware Solution:
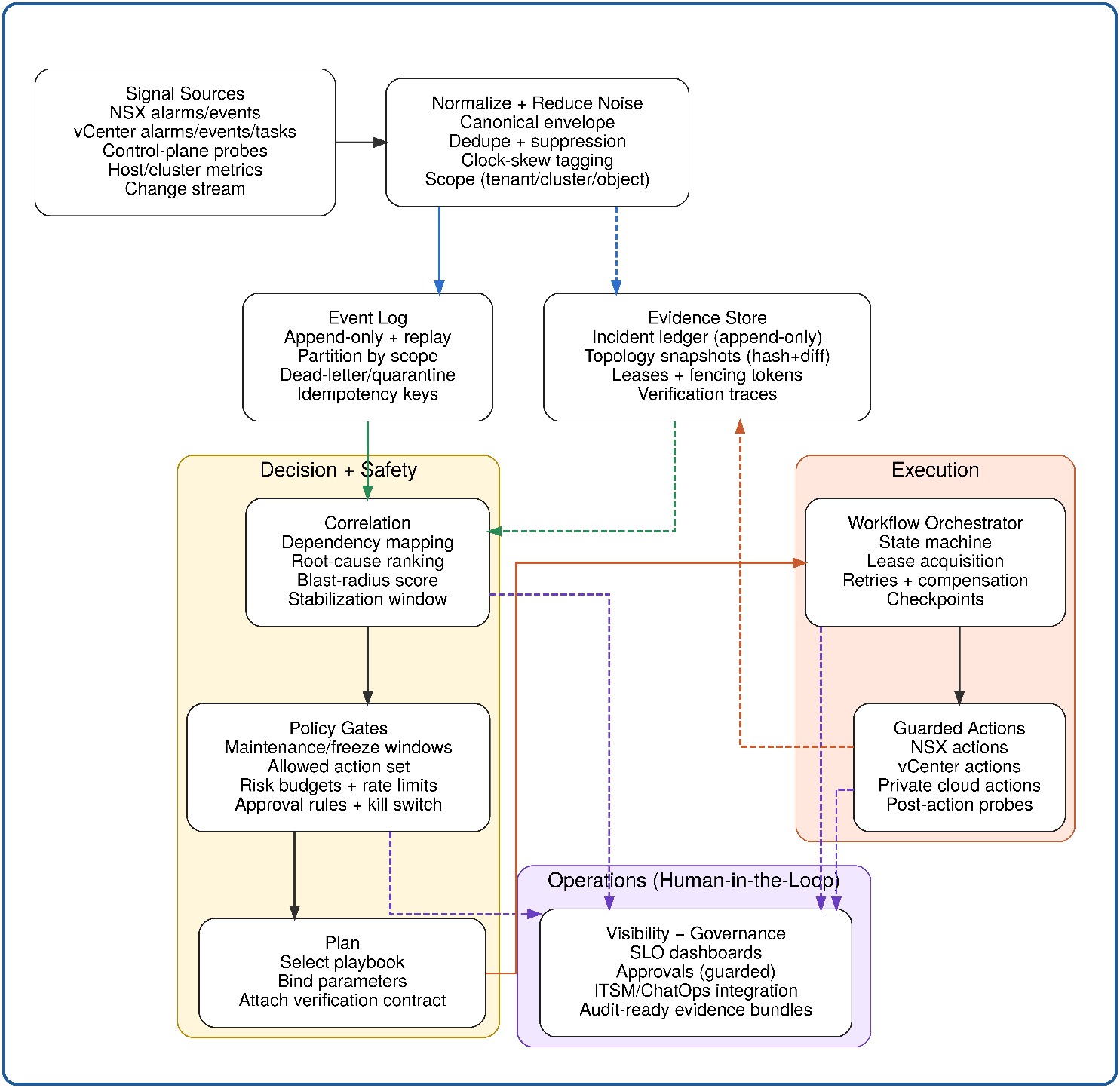
Разделение трёх плоскостей (обнаружение, принятие решений, выполнение) с изоляцией поверхностей сбоя по всему управляющему контуру.
Динамический граф зависимостей реального времени, непрерывно обновляемый из потоков событий VMware NSX и vCenter Server, заменяющий статические наборы правил, которые расходятся с реальной топологией.
Трёхвходная модель причинно-следственной корреляции (сила доказательств, временной порядок, направленность зависимости), отличающая причинно-следственные цепочки от совпадающих событий.
Вычисление радиуса проблемы перед выполнением - входной параметр шлюза, обеспечивающий пропорциональное применение политик до совершения любого действия.
Модель фазовых границ (стабилизация, выполнение, верификация), преобразующая событийные осцилляции в демпфированную петлю обратной связи с гистерезисом.
Структура контракта выполнения (триггер, объявление шлюза, спецификация шагов, контракт верификации), принудительно обеспечивающая допустимость области действия и актуальность топологии как системных ограничений.
Единый журнал с возможностью только дополнения, формирующий идентичные записи для автоматизированных и управляемых людьми путей разрешения инцидентов — для целей управления и воспроизведения после инцидента.
Для сбоев в охватываемой области результат — это ограниченное, воспроизводимое время восстановления в любое время суток без участия оператора. Для сбоев в охватываемой области, где автоматическое устранение не может быть санкционировано, результат — детерминированный пакет доказательств, заменяющий воспоминания инженера структурированной, воспроизводимой передачей дел.
Архитектура: обнаружение, принятие решений и выполнение
Автономное самовосстановление разделяет обнаружение, принятие решений и выполнение на отдельные плоскости с единственными, тестируемыми контрактами между ними. Объединение этих функций — более простой подход — разделяет поверхность сбоя между всеми тремя: ошибка в движке выполнения может повредить доказательства, от которых зависит модель корреляции; всплеск объёма тревог может лишить ресурсов оценщика шлюзов; неправильно настроенный шлюз может заблокировать нормализацию сигналов. Разделение устраняет эти режимы взаимозаражения сбоев.
Плоскость обнаружения преобразует необработанные потоки тревог VMware NSX и vCenter Server в стабильные, дискретные кандидаты на инцидент. Конвейер нормализует форматы событий из разных источников, сворачивает избыточные сигналы и применяет окно задержки для фильтрации переходных изменений состояния. Кандидаты, пересекающие границу плоскости, — это подтверждённые, стабильные единицы, единственная форма, которую модель корреляции способна корректно обработать.
Плоскость принятия решений выполняет причинно-следственную корреляцию по динамическому графу зависимостей приватного облака перед оценкой шлюза, формируя ранжированную гипотезу первопричины с оценками уверенности и вычисленной оценкой радиуса проблемы. Плоскость выдаёт ровно один из двух результатов: санкционированное шлюзом разрешение на выполнение или эскалацию с полным пакетом доказательств.
Плоскость выполнения получает токен, ограниченный минимально жизнеспособной областью сбоя, запускает версионированный идемпотентный контрольно-точечный плейбук и закрывает инцидент только после того, как независимая верификация постусловий подтверждает стабильное восстановление в течение окна стабильности. Каждый переход состояния дополняет журнал инцидента.
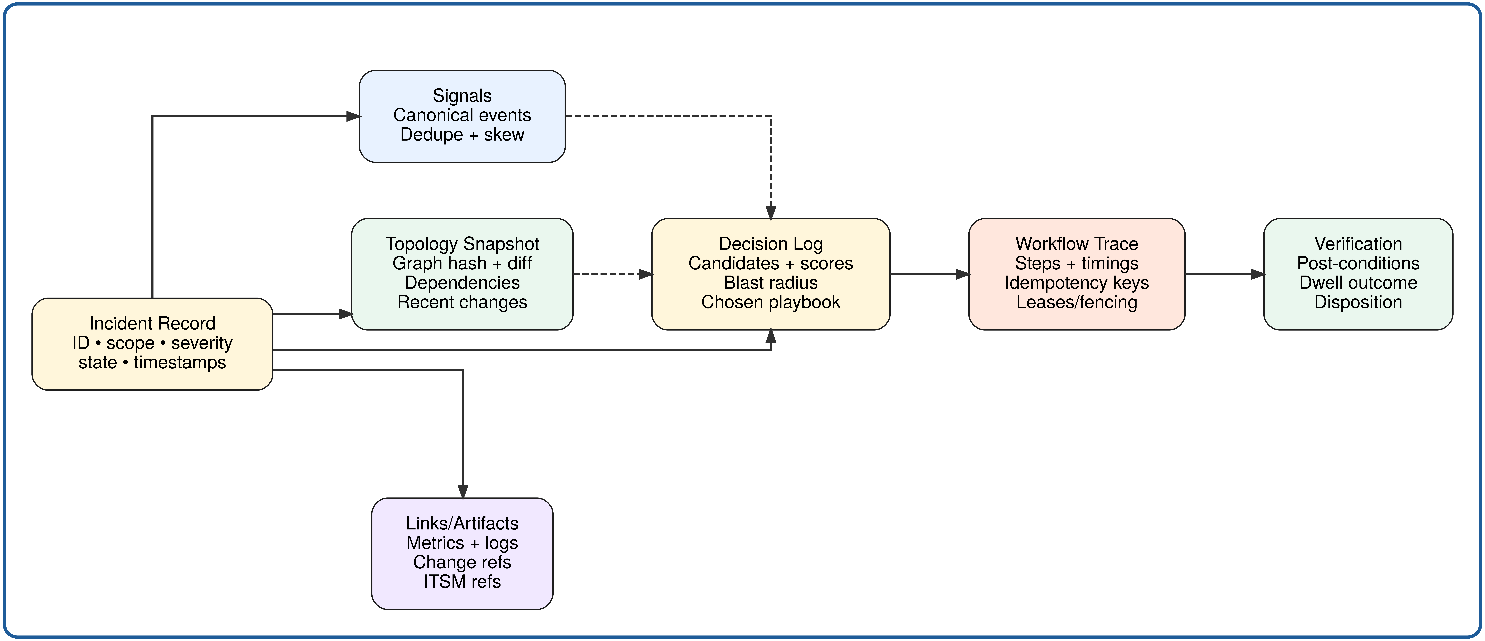
Журнал инцидентов
Автономное самовосстановление формирует структурированный журнал с возможностью только дополнения для каждого инцидента вне зависимости от пути разрешения. Последовательно фиксируются пять категорий: необработанные и нормализованные сигналы с результатами подавления; снимок топологии на момент обнаружения; полная запись решений, включая результаты корреляции, ранжирование первопричин, оценку радиуса проблемы и трассировку оценки шлюза; трассировка workflow с метаданными шагов и идентификаторами аренды; и результат верификации с результатами постусловий и диспозицией окна стабильности.
Автоматизированные и управляемые людьми пути формируют одинаковую структуру записи — это требование управляемости, а не предпочтение проектирования. Воспроизведение детерминировано: по одному и тому же журналу два рецензента реконструируют одинаковую временную шкалу инцидента.
Итог
Автономное самовосстановление обрабатывает определённое подмножество сбоев плоскости управления NSX и vCenter в приватном облаке Azure VMware Solution. Система не обрабатывает сбои плоскости данных, сбои хранилища, сбои гипервизора, аппаратные сбои или сбои плоскости управления вне смоделированного графа зависимостей. Она не запускает произвольные скрипты, не обходит управление доступом на основе ролей и не переопределяет границы изоляции тенантов. Ограниченная область является источником надёжности системы — система, пытающаяся устранять всё подряд, несёт режимы сбоя, пропорциональные её охвату.
Когда автономное самовосстановление не может предпринять действий, формируемый им пакет доказательств обеспечивает полную структурированную передачу для ответа оператора.
Многие VMware-инфраструктуры сегодня находятся в переходной стадии: организации продолжают использовать
vSphere-кластеры, но постепенно переходят к модели Software-Defined Data Center и частного облака на базе VMware Cloud Foundation (VCF).
Полностью перестраивать инфраструктуру с нуля в производственной среде обычно невозможно. Там уже работают
десятки или сотни виртуальных машин, поэтому перенос на новую платформу должен происходить максимально
аккуратно. Именно для таких сценариев VMware предлагает механизм Brownfield-интеграции.
Этот подход позволяет смигрировать существующую инфраструктуру vSphere на VMware Cloud Foundation без
переустановки среды и без миграции виртуальных машин. Подробно этот процесс рассмотрел Tarsio Moraes в своем видео:
Что такое Brownfield-апгрейд
Brownfield-подход означает интеграцию уже существующей инфраструктуры в новую платформу без полного
развертывания новой среды.
В VMware-экосистеме это означает, что существующий vCenter Server,
кластеры ESX и запущенные виртуальные машины могут быть импортированы
в VCF как отдельный Workload Domain.
Таким образом инфраструктура сохраняет текущие рабочие нагрузки, но получает централизованное управление,
автоматизированное lifecycle-обновление и интеграцию сетевой платформы NSX.
Архитектура до и после интеграции
Исходная инфраструктура
Типичная среда включает vSphere 8, один или несколько кластеров ESXi,
vCenter Server и систему хранения — например vSAN или внешние датасторы.
Сетевая конфигурация обычно построена на распределенном коммутаторе Distributed Switch.
В такой архитектуре управление вычислениями, сетью и мониторингом может
осуществляться через разные инструменты.
После интеграции в VCF
После импорта инфраструктура становится частью платформы VMware Cloud Foundation.
Появляется централизованное управление через компоненты VCF, а инфраструктура
разделяется на management domain и workload domains.
Также стоит учитывать изменения в продуктовой линейке VMware:
многие функции бывшей линейки Aria теперь встроены непосредственно в VMware Cloud Foundation (как функционал модуля Operations).
Подготовка инфраструктуры
Перед запуском Brownfield-апгрейда необходимо убедиться,
что инфраструктура соответствует требованиям совместимости.
В первую очередь проверяются версии компонентов:
vSphere, vCenter Server и ESXi (теперь он снова называется ESX). Кроме того,
важно убедиться в совместимости оборудования через VMware Compatibility Guide.
Также необходимо проверить базовые инфраструктурные сервисы:
DNS, NTP, доступность сетей управления и состояние датасторов.
Особенно важно убедиться, что DNS корректно разрешает имена
хостов ESX, vCenter и будущих узлов NSX Manager.
Подготовка среды управления
Перед импортом vSphere-среды необходимо подготовить управляющие компоненты VMware Cloud Foundation.
К ним относятся VCF Fleet Management и VCF Operations.
Эти сервисы отвечают за централизованное управление инфраструктурой,
мониторинг и lifecycle-операции.
На этом этапе стоит проверить доступность management-компонентов,
валидность сертификатов и сетевую связность между сервисами управления и vCenter.
Использование VCF Import Tool
Для интеграции существующей среды используется специальный инструмент —
VCF Import Tool.
Он анализирует конфигурацию vSphere,
выполняет проверку совместимости и подготавливает инфраструктуру к импорту.
Перед запуском процесса выполняется серия pre-check проверок,
которые анализируют сеть, лицензии, сертификаты, конфигурацию кластеров
и параметры хранения.
Если обнаружены ошибки или предупреждения, их необходимо устранить
до начала импорта.
Импорт vCenter как Workload Domain
После завершения подготовительных этапов можно приступать к импорту
существующего vCenter.
В интерфейсе VCF создаётся новый workload domain,
после чего указываются параметры подключения к существующему vCenter.
После проверки параметров запускается автоматический рабочий процесс (workflow),
который выполняет регистрацию vCenter в инфраструктуре VCF.
С этого момента среда становится частью VMware Cloud Foundation.
Развертывание NSX
Следующий этап — интеграция сетевой платформы NSX.
Если NSX ранее не использовался, VMware Cloud Foundation может автоматически
развернуть NSX Manager cluster и подготовить хосты ESX.
Если NSX уже установлен в инфраструктуре,
он может быть импортирован вместе с workload domain.
Пост-апгрейд проверки
После завершения интеграции необходимо провести проверку состояния среды.
Стоит убедиться, что workload domain корректно отображается
в интерфейсе VCF, хосты ESX подключены,
датасторы доступны, а виртуальные машины работают без ошибок.
Дополнительно рекомендуется протестировать ключевые операции виртуализации:
vMotion, создание снапшота и сетевую связность между виртуальными машинами.
Итог
Brownfield-апгрейд позволяет перевести существующую инфраструктуру
vSphere 8 в модель VMware Cloud Foundation 9 без полного
перестроения среды.
Этот подход сохраняет текущие рабочие нагрузки,
централизует управление инфраструктурой
и позволяет постепенно перейти к архитектуре частного облака.
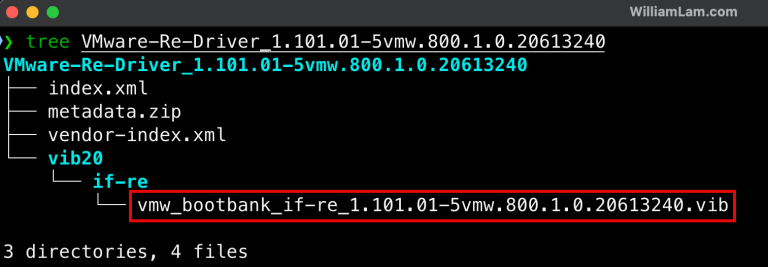
В 2026 году сообщество ESX получило сразу два важнейших обновления, которые расширяют возможности использования популярных сетевых устройств Realtek RTL8157 и RTL8156BG в виртуальной инфраструктуре VMware. Эти обновления особенно актуальны для лабораторных сред, мини-ПК и других систем с оборудованием, не поддерживаемым «из коробки» стандартным инсталлятором ESX.
Интеграция Realtek Network Driver Fling в бесплатный установочный ISO ESXi
Одной из ключевых проблем при установке ESXi 8 Update 3 на ПК с сетевыми адаптерами Realtek является отсутствие драйверов для этих сетевых контроллеров в стандартном установщике. Чтобы обойти это ограничение, было разработано решение для сообщества пользователей - Realtek Network Driver Fling (пока еще недоступно для ESX 9, но скоро будет).
Этот драйвер не является официальным продуктом Realtek, а представляет собой компонент Fling (экспериментальный инструмент для расширения ESXi), который обеспечивает базовую поддержку PCIe-сетевых адаптеров Realtek. Об этом недавно написал Вильям Лам.
Драйвер поддерживает ряд популярных моделей Realtek:
RTL8111 — 1 GbE
RTL8125 — 2,5 GbE
RTL8126 — 5 GbE
RTL8127 — 10 GbE
Проблема в том, что в бесплатных ISO-образах ESXi отсутствует пакет offline bundle (который можно было бы включить стандартным способом). Однако, как показано в одной из публикаций Вильяма Лама, можно вручную интегрировать драйвер в ISO-установщик ESXi 8.0 Update 3e.
Процесс включает:
Загрузку ISO-образа ESXi и архива драйвера Realtek Network Driver Fling.
Извлечение модуля драйвера и переименование в специальный файл (например, ifre.v00).
Добавление этого модуля в загрузочный конфигурационный файл ISO (boot.cfg) для автоматической загрузки при старте установщика.
Установку ESXi с загрузочного носителя и копирование модуля драйвера на установленную систему для постоянного использования.
Этот метод позволяет запускать ESXi даже там, где стандартный инсталлятор не видит сетевой адаптер — например, на небольших ПК или системах без Intel-сетевых контроллеров.
Расширение USB-сетевого драйвера — поддержка новых чипов Realtek
Другая важная новость касается USB Native Network Driver для ESXi, ещё одного модуля Fling, который добавляет поддержку USB-сетевых адаптеров. Сегодня этот драйвер поддерживает уже более 25 различных чипсетов, а в свежем обновлении разработчики добавили поддержку USB-адаптеров Realtek RTL8157 (5 GbE) и RTL8156BG (2,5 GbE).
Это означает, что пользователи могут подключать к ESXi внешние USB-сетевые адаптеры и использовать их для сетевого трафика без необходимости установки PCIe-карты. Такие адаптеры, особенно в формате USB-C или USB-A, часто используются в компактных рабочих станциях и ноутбуках.
Примеры совместимых устройств (которые можно использовать для тестов и сборок лабораторных систем):
USB-A - 2,5 GbE адаптер на базе RTL8156BG
USB-C - 5 GbE адаптер на базе RTL8157
Установка обновлённого USB-сетевого драйвера производится как с помощью offline bundle (через команду esxcli software component apply), так и путём интеграции в ISO-образ ESXi аналогично описанному в статье Вильяма процессу.
Почему это важно
До появления этих драйверов ESXi мог не видеть сетевые устройства Realtek, что делало невозможной установку гипервизора на недорогие системы или платформы с USB-адаптерами. Решения Fling активно развиваются сообществом и дают пользователям гибкие способы расширения функциональности ESXi без официальной поддержки от производителя.
Теперь вы можете:
Интегрировать новейший Realtek PCIe-драйвер прямо в установщик ESXi.
Использовать современные USB-сетевые адаптеры с высокими скоростями передачи (2,5 GbE и 5 GbE).
Поддерживать широкий спектр оборудования в лабораторных или домашних средах.
VMware недавно опубликовала обновлённый набор технических руководств, которые приводят рекомендации в соответствие с архитектурой эпохи VMware Cloud Foundation
и с новыми возможностями приложений Microsoft, включая SQL Server 2025 и Windows Server 2025.
Если вы планируете развёртывание VCF, модернизируете существующие среды, стандартизируете платформу, обновляете парк SQL Server или модернизируете инфраструктуру идентификации, мы рекомендуем ознакомиться с этими документами до того, как будет окончательно утверждён ваш следующий дизайн-воркшоп, цикл закупок или план миграции.
Руководство 1: Проектирование Microsoft SQL Server на VMware Cloud Foundation
Для многих команд решение о виртуализации SQL Server уже принято. Как говорится в руководстве: «вопрос больше не в том, виртуализировать ли SQL Server, а в том, как…». И это «как» существенно изменилось в мире VCF. Платформа стала более регламентированной, операционная модель — более стандартизированной, а поддерживающие возможности (хранилище, сеть, управление жизненным циклом, безопасность) эволюционировали с учётом развития аппаратных возможностей и операционных методик.
Обновлённое руководство предназначено для читателей, которые уже понимают как VCF, так и SQL Server. Оно ориентировано на несколько ролей: архитекторов, инженеров/администраторов и DBA.
Несколько моментов, на которые стоит обратить внимание:
Современные рекомендации по CPU и NUMA теперь учитывают и новое поведение топологии в эпоху VCF. Руководство рассматривает «новые параметры конфигурации топологии vNUMA в VMware Cloud Foundation (VCF)» и объясняет, почему это поведение важно для крупных виртуальных машин SQL Server.
Чёткая и обновлённая позиция по CPU hot plug в эпоху SQL Server 2025. В руководстве прямо указано: CPU Hot-Add больше не поддерживается в SQL Server 2025, и его не следует включать на таких виртуальных машинах.
Рекомендации по хранилищу, соответствующие направлению развития VCF. Если вы оцениваете архитектурные варианты vSAN, руководство объясняет, почему vSAN Express Storage Architecture (ESA) привлекателен для заказчиков, переходящих на более современное оборудование, и подчёркивает возможности эффективности ESA, такие как глобальная дедупликация и преимущества сжатия для нагрузок баз данных.
Пояснения по устаревающим функциям, влияющим на долгоживущие архитектуры. Если в вашей текущей архитектуре активно используются vVols, учтите, что Virtual Volumes объявлены устаревшими, начиная с VCF 9.0 и VMware vSphere Foundation 9.0 (полный отказ запланирован в будущих релизах).
Операционная реалистичность для мобильности и обслуживания. Руководство рассматривает использование multi-NIC vMotion для снижения риска зависания (stun) при миграции крупных, потребляющих много памяти виртуальных машин SQL, а также отмечает, что VCF внедряет vMotion Notifications, чтобы помочь чувствительным к задержкам и кластер-осведомлённым приложениям безопаснее обрабатывать миграции.
Если вы принимаете решения - это тот документ, который снижает объём переработок, вызванных неожиданностями. Если вы технический специалист - это тот документ, который не позволит вам унаследовать архитектуру в стиле «it depends», которая позже приведёт к простою.
Руководство 2: Проектирование Microsoft SQL Server для высокой доступности на VMware Cloud Foundation
Второе руководство сосредоточено там, где ставки особенно высоки: корректное проектирование доступности SQL Server на VCF без смешивания устаревших предположений, неподдерживаемых конфигураций или подхода «потом исправим» в кластеризации.
Оно написано для смешанной аудитории, включая DBA, администраторов VMware, архитекторов и IT-руководителей. И в нём ясно указано, что «доступность» — это не функция, которую добавляют в конце; выбранная модель защиты должна определяться бизнес-требованиями.
Несколько особенно практичных обновлений:
Реалии доступности SQL Server 2025, чётко сопоставленные с механизмами защиты. Руководство связывает уровни защиты с современными возможностями обеспечения доступности SQL Server, подчёркивает области, где SQL Server 2025 усиливает архитектуры на базе Availability Groups (AG), и отмечает, что Database Mirroring удалён в SQL Server 2025.
Рекомендации по согласованию жизненного цикла, которые действительно важны для IT-руководства. Начиная с SQL Server 2025, отмечается, что более старые версии Windows Server вышли из основной поддержки, и рекомендуется использовать Windows Server 2025 или Windows Server 2022 при наличии совместимости — прямой переход к поддерживаемым и обоснованным платформам.
Современные варианты кластеризации с общими дисками без навязывания устаревших архитектур. Руководство указывает, что в средах эпохи VCF 9 семантика общих дисков для FCI может быть реализована современными способами — подчёркивается использование Clustered VMDKs и явно обозначается движение в сторону отказа от устаревших зависимостей.
Рекомендации по DRS anti-affinity, предотвращающие «самоорганизованные» события HA. Если узлы кластера SQL работают на одном и том же хосте ESXi «потому что так решил DRS», это не высокая доступность, а отложенный инцидент. Настройте соответствующие правила DRS, чтобы узлы кластера были физически разделены.
Требования к vMotion Application Notification, изложенные подробно. Руководство описывает использование уведомлений приложений, включая требования, такие как актуальные VMware Tools и рекомендуемая настройка таймаутов — именно те детали, которые команды часто выясняют в условиях уже упавшей системы.
Рекомендации по vSAN ESA, отражающие текущие возможности. Указывается направление политик ESA и отмечается глобальная дедупликация (впервые представленная в VCF 9.0) как рекомендуемая для определённых сценариев Availability Group SQL Server в пределах одного кластера vSAN.
Это то руководство, которое вы передаёте команде, когда бизнес говорит: «нам нужна более высокая доступность», — и вы хотите, чтобы ответом стало инженерно проработанное решение.
Руководство 3: Виртуализация служб домена Active Directory на VMware Cloud Foundation
Active Directory (AD) Domain Services (DS) — одна из тех служб, о которых не думают до тех пор, пока всё не перестанет работать. Обновлённое руководство по AD DS прямо признаёт это, указывая, что многие организации справедливо рассматривают AD DS как по-настоящему критичное для бизнеса приложение, поскольку аутентификация, доступ к ресурсам и бесчисленные рабочие процессы зависят от него.
Оно также напрямую обращается к сохраняющемуся рефлексу «физического контроллера домена». Благодаря развитию Windows Server и зрелым практикам VCF, в руководстве говорится, что эти улучшения теперь позволяют организациям «безопасно виртуализировать сто процентов своей инфраструктуры AD DS».
Существенно обновлены не общие рекомендации «виртуализируйте это», а современный набор функций и механизмов защиты, которые меняют подход к проектированию и защите виртуальных контроллеров домена:
В руководстве указано, что лишь несколько усовершенствований существенно изменяют прежние рекомендации, включая Virtualization-Based Security (VBS), Secure Boot, шифрование на уровне виртуальной машины и улучшенную синхронизацию времени в гостевых ВМ — и эти изменения учтены там, где это необходимо.
Документ явно ориентирован на несколько аудиторий (архитекторов, инженеров/администраторов и руководителей/владельцев процессов), что важно для AD DS, поскольку проектирование и эксплуатация неразделимы.
Подчёркиваются операционные меры защиты при восстановлении после сбоев. Например, рекомендуется использовать приоритет перезапуска ВМ в vSphere HA, чтобы ключевые инфраструктурные службы запускались раньше после аварийного восстановления.
Подробно рассматриваются механизмы обеспечения целостности в эпоху виртуализации (например, поведение VM-Generation ID), созданные специально для устранения исторических опасений, связанных со снапшотами и откатами.
Если вы модернизируете инфраструктуру идентификации, консолидируете датацентры или строите частное облако на базе VCF с сильной позицией по безопасности, этот документ обязателен к прочтению. AD DS — это не просто ещё одна рабочая нагрузка. Это сущность, от которой зависит работа всего вашего стека.
Руководство 4: Запуск Microsoft SQL Server Failover Cluster Instance на VMware vSAN платформы VMware Cloud Foundation 9
Если ваша модель обеспечения доступности по-прежнему основана на кластеризации с общими дисками — будь то из-за ограничений приложений, операционных предпочтений или необходимости сохранить модель SQL Server FCI — это руководство является практическим дополнением «как это реально работает на VCF 9» к более общим рекомендациям по HA. Это эталонная архитектура для запуска Microsoft SQL Server Failover Cluster Instance (FCI) с использованием общих дисков на базе vSAN, валидированная как для стандартного кластера vSAN, так и для сценария растянутого кластера vSAN.
Несколько моментов, на которые стоит обратить внимание:
Нативная поддержка WSFC + общих дисков на vSAN (с подробным описанием механики). В VCF 9 «vSAN обеспечивает нативную поддержку виртуализированных Windows Server Failover Clusters (WSFC)» и «поддерживает SCSI-3 Persistent Reservations (SCSI3PR) на уровне виртуального диска» — ключевое требование для арбитража общих дисков в WSFC.
Две настройки конфигурации, от которых зависит работоспособность общих дисков. Указывается, что общие диски должны быть подключены к контроллеру с параметром SCSI Bus Sharing, установленным в Physical, и что «режим диска для всех дисков в кластере должен быть установлен в Independent – Persistent», чтобы избежать неподдерживаемой семантики снапшотов на общих дисках.
Операционные особенности растянутого кластера: задержки, размещение и кворум являются частью архитектуры. Рекомендуется «менее четырёх миллисекунд межсайтовой (round trip) задержки» для SQL-баз данных уровня tier-1 в растянутых кластерах vSAN, а также подчёркивается необходимость правил DRS VM/Host для разделения узлов WSFC по разным хостам.
Также рекомендуется использовать диск-свидетель кворума, чтобы растянутый кластер сохранял доступность witness-диска при отказе сайта без остановки службы кластера FCI.
Практический путь миграции с SAN pRDM на общие VMDK vSAN. С самого начала подчёркивается: «перед миграцией настоятельно рекомендуется создать резервную копию», и отмечается, что миграция выполняется офлайн. Описываются шаги по остановке роли кластера, выключению узлов и использованию Storage Migration для преобразования pRDM в VMDK на vSAN ± с обходным решением через PowerCLI (включая пример кода) в случае, если выбор формата диска в мастере Migrate недоступен.
Это руководство, которое вы передаёте команде, когда требование звучит как «нам нужна семантика FCI», и вы хотите получить осознанную, поддерживаемую архитектуру.
Что дальше
Если вы активно проектируете, обновляете или мигрируете инфраструктуру, рассматривайте эти руководства в контексте команд:
Команды платформы: сначала прочитайте руководство по SQL Server, чтобы согласовать значения по умолчанию вычислений/хранилища/сети с поведением SQL.
DBA и инженеры инфраструктуры: прочитайте руководство по HA до того, как зафиксируете модель кластеризации, стратегию хранения и модель обслуживания.
Команды по идентификации и безопасности: прочитайте руководство по AD DS, чтобы согласовать меры настройки, восстановления и операционные процессы с современными механизмами защиты виртуализации.
Команды, использующие (или стандартизирующие) SQL Server FCI: прочитайте руководство по FCI на vSAN, чтобы зафиксировать требования к общим дискам, позицию по политике хранения и ограничения растянутого кластера до внедрения.
Ниже приведены прямые ссылки для скачивания упомянутых документов:
Наверняка не всем из вас знаком ресурс virten.net — технический портал, посвящённый информации, новостям, руководствам и инструментам для работы с продуктами VMware и виртуализацией. Сайт предлагает полезные ресурсы как для ИТ-специалистов, так и для энтузиастов виртуализации, включая обзоры версий, документацию, таблицы сравнений и практические руководства.
Там можно найти:
Новости и статьи о продуктах VMware (релизы, обновления, сравнения версий, технические обзоры).
Полезные разделы по VMware vSphere, ESX, vCenter и другим продуктам, включая истории релизов, конфигурационные лимиты и различия между версиями.
Практические инструменты и утилиты, такие как декодеры SCSI-кодов, RSS-трекер релизов (vTracker), помощь по OVF/PowerShell, события vCenter и JSON-репозиторий полезных данных.
Давайте посмотрим, что на этом сайте есть полезного для администраторов инфраструктуры VMware Cloud Foundation.
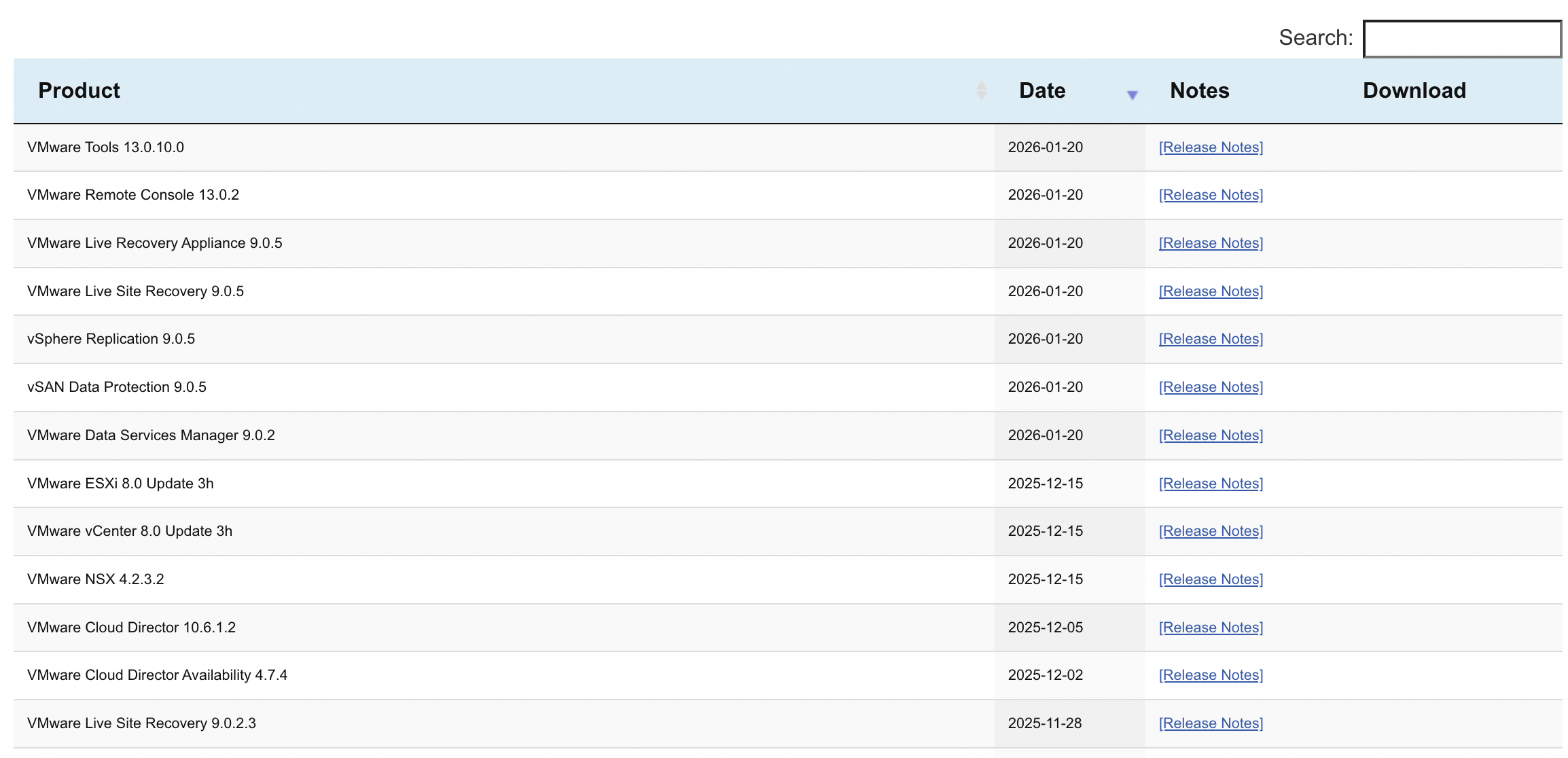
Эта страница содержит список продуктов, выпущенных компанией VMware. vTracker автоматически обновляется, когда на сайте vmware.com становятся доступны для загрузки новые продукты (GA — общедоступный релиз). Если вы хотите получать уведомления о выходе новых продуктов VMware, подпишитесь на RSS-ленту. Вы также можете использовать экспорт в формате JSON для создания собственного инструмента. Не стесняйтесь оставлять там комментарии, если у вас есть предложения по новым функциям.
Если вы просто хотите узнать, какая версия того или иного продукта VMware сейчас актуальна, самый простой способ - это посмотреть вот эту таблицу с функцией поиска:
В этом разделе представлен полный перечень релизов флагманского гипервизора VMware ESX (ранее ESXi). Все версии, выделенные жирным шрифтом, доступны для загрузки. Все патчи указаны под своими официальными названиями релизов, датой выхода и номером билда. Обратите внимание, что гипервизор ESXi доступен начиная с версии 3.5.
Если вы столкнулись с какими-либо проблемами при работе с этим сайтом или заметили отсутствие сборок, пожалуйста, свяжитесь с автором.
Эта страница представляет собой коллекцию заранее настроенных фрагментов PowerShell-скриптов для развертывания OVF/OVA. Идея заключается в ускорении процесса развертывания, если вам необходимо устанавливать несколько виртуальных модулей, выполнять повторное развертывание из-за неверных входных данных или сохранить файл в качестве справочного примера для будущих установок.
Просто заполните подготовленные переменные так же, как вы обычно делаете это в клиенте vSphere, и запустите скрипт. Все шаблоны используют одинаковую последовательность действий и тексты подсказок из мастера развертывания. Необязательные параметры конфигурации можно закомментировать. Если у параметров есть значения по умолчанию, они уже заполнены.
Ошибки или предупреждения SCSI в логах и интерфейсе ESX отображаются с использованием 6 кодов состояния. Эта страница преобразует эти коды, полученные от хостов ESX, в понятную для человека информацию о состоянии подсистемы хранения. В системном журнале vmkernel.log на хостах ESXi версии 5.x или 6.0 вы можете увидеть записи, подобные приведённым ниже. На странице декодера вы можете ввести нужные числа в форму и получить пояснения по сообщениям SCSI:
В этой статье мы завершаем рассказывать об итогах 2025 года в сферах серверной и настольной виртуализации на базе российских решений. Сегодня мы поговорим о том, как их функционал соотносится с таковым от ведущего мирового производителя - VMware.
Первую часть статьи можно прочитать тут, вторая - доступна здесь.
Сравнение с VMware vSphere
Как же отечественные решения выглядят на фоне VMware vSphere, многолетнего эталона в сфере виртуализации? По набору функций российские платформы стремятся обеспечить полный паритет с VMware – и во многом этого уже достигли. Однако при более глубоком сравнении выявляются отличия в зрелости, экосистеме и опыте эксплуатации.
Функциональность
Почти все базовые возможности VMware теперь доступны и в отечественных продуктах: от управления кластерами, миграции ВМ на лету и снапшотов до сетевой виртуализации и распределения нагрузки. Многие платформы прямо ориентируются на VMware при разработке. Например, SpaceVM позиционирует свои компоненты как аналоги VMware: SDN Flow = NSX, FreeGRID = NVIDIA vGPU (для Horizon), Space Dispatcher = Horizon Connection Server. ZVirt, Red, ROSA, SpaceVM – все поддерживают VMware-совместимые форматы виртуальных дисков (VMDK/OVA) и умеют импортировать ВМ из vSphere.
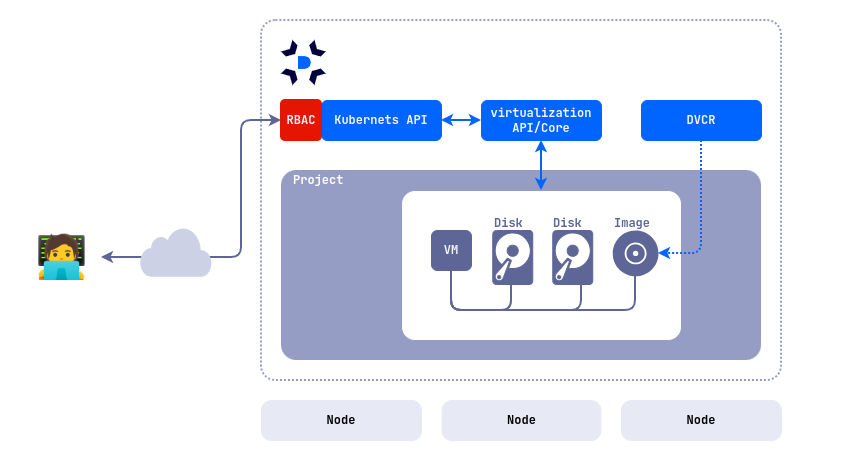
То есть миграция технически осуществима без кардинальной переделки ВМ. Live Migration, HA, кластеры, резервирование – эти функции стали стандартом де-факто, и российские продукты их предоставляют. Более того, появились и некоторые новые возможности, которых нет в базовом издании vSphere: например, интеграция с Kubernetes (KubeVirt) в решении Deckhouse от Flant позволяет управлять ВМ через Kubernetes API – VMware предлагает нечто подобное (vSphere with Tanzu), но это отдельно лицензируемый модуль.
Другой пример – поддержка облачных сервисов: некоторые отечественные платформы сразу рассчитаны на гибридное облако, тогда как VMware требует vCloud Suite (сейчас это часть платформы VMware Cloud Foundation, VCF). Тем не менее, зрелость функционала различается: если у VMware каждая возможность отполирована годами использования по всему миру, то у новых продуктов возможны баги или ограничения. Эксперты отмечают, что просто сравнить чекбоксы “есть функция X” – недостаточно, важна реализация. У VMware она, как правило, образцовая, а у российского аналога – может требовать ручных доработок. Например, та же миграция ВМ в российских системах работает, но иногда возникают нюансы с live migration при специфических нагрузках (что-то, что VMware давно решила).
Производительность и масштабирование
VMware vSphere славится стабильной работой кластеров до 64 узлов (в v7 – до 96 узлов) и тысяч ВМ. В принципе, и наши решения заявляют сопоставимый масштаб, но проверены они временем меньше. Как упоминалось, некоторые продукты испытывали сложности уже на 50+ хостах. Тем не менее, для 90% типовых инсталляций (до нескольких десятков серверов) разницы в масштабируемости не будет. По производительности ВМ – разница тоже минимальна: KVM и VMware ESXi показывают близкие результаты бенчмарков. А оптимизации вроде vStack с 2% overhead вообще делают накладные расходы незаметными. GPU-виртуализация – здесь VMware имела преимущество (технология vGPU), но сейчас SpaceVM и другие сократили отставание своим FreeGRID. Зато VMware до последнего времени обеспечивала более широкую поддержку оборудования (драйверы для любых RAID, сетевых карт) – российские ОС и гипервизоры поддерживают далеко не все модели железа, особенно новейшие. Однако ситуация улучшается за счет локализации драйверов и использования стандартных интерфейсов (VirtIO, NVMe и пр.).
Совместимость и экосистема
Ключевое различие – в экосистеме смежных решений. Окружение VMware – это огромный пласт интеграций: сотни backup-продуктов, мониторингов, готовых виртуальных апплаенсов, специальных плагинов и т.д. В российской экосистеме такого разнообразия пока нет. Многие специализированные плагины и appliance, рассчитанные на VMware, не будут работать на отечественных платформах.
Например, виртуальные апплаенсы от зарубежных вендоров (сетевые экраны, балансировщики), выпускались в OVF под vSphere – их можно включить и под KVM, но официальной поддержки может не быть. Приходится либо искать аналогичный российский софт, либо убеждаться, что в open-source есть совместимый образ. Интеграция с enterprise-системами – тоже вопрос: у VMware был vCenter API, поддерживаемый многими инструментами. Отечественным гипервизорам приходится писать собственные модули интеграции. Например, не все мониторинговые системы «из коробки» знают про zVirt или SpaceVM – нужно настраивать SNMP/API вручную.
Такая же ситуация с резервным копированием: знакомые всем Veeam и Veritas пока не имеют официальных агентов под наши платформы (хотя Veeam частично работает через стандартный SSH/VIX). В итоге на текущем этапе экосистема поддержки у VMware гораздо более развита, и это объективный минус для новых продуктов. Однако постепенно вокруг популярных российских гипервизоров формируется своё сообщество: появляются модули для Zabbix, адаптеры для Veeam через скрипты, свои решения backup (например, CyberProtect для Cyber Infrastructure, модуль бэкапа в VMmanager и т.п.).
Надёжность и поддержка
VMware десятилетиями оттачивала стабильность: vSphere известна редкими «падениями» и чётким поведением в любых ситуациях. Российским платформам пока ещё не хватает шлифовки – пользователи отмечают, что полностью «скучной» работу с ними назвать нельзя. Периодически инженерам приходится разбираться с нетривиальными багами или особенностями. В пример приводят трудоёмкость настройки сетевой агрегации (линков) – то, что на VMware привычно, на некоторых отечественных системах реализовано иначе и требует дополнительных манипуляций.
При обновлении версий возможны проблемы с обратной совместимостью: участники рынка жалуются, что выход каждого нового релиза иногда «ломает» интеграции, требуя доработки скриптов и настроек. Отсюда повышенные требования к квалификации админов – нужно глубже понимать «под капотом», чем при работе с отлаженной VMware. Но есть и плюс: почти все российские вендоры предоставляют оперативную техподдержку, зачастую напрямую от команд разработчиков. В критических случаях они готовы выпустить патч под конкретного заказчика или дать обходной совет. В VMware же, особенно после перехода на Broadcom, поддержка стала менее клиентоориентированной для средних клиентов. В России же каждый клиент на вес золота, поэтому реакция, как правило, быстрая (хотя, конечно, уровень экспертизы разных команд разнится).
Стоимость и лицензирование
Ранее VMware имела понятную, хоть и недешёвую модель лицензирования (по процессорам, +опции за функции). После покупки Broadcom стоимость выросла в разы, а бессрочные лицензии отменены – только подписка. Это сделало VMware финансово тяжелее для многих. Отечественные же продукты зачастую предлагают более гибкие условия: кто-то лицензирует по ядрам, кто-то по узлам, у кого-то подписка с поддержкой. Но в целом ценовой порог для легального использования ниже, чем у VMware (тем более, что последняя официально недоступна, а «серыми» схемами пользоваться рискованно). Некоторые российские решения и вовсе доступны в рамках господдержки по льготным программам для госучреждений. Таким образом, с точки зрения совокупной стоимости владения (TCO) переход на отечественную виртуализацию может быть выгоден (но может и не быть), особенно с учётом локальной техподдержки и отсутствия валютных рисков.
Подведём коротко плюсы и минусы российских платформ относительно VMware.
Плюсы отечественных решений:
Импортонезависимость и соответствие требованиям. Полное соблюдение требований законодательства РФ для госкомпаний и КИИ (реестр ПО, совместимость с ГОСТ, сертификация ФСТЭК у компонентов).
Локальная поддержка и доработка. Возможность напрямую взаимодействовать с разработчиком, получать кастомные улучшения под свои задачи и быстро исправлять проблемы в сотрудничестве (что практически невозможно с глобальным вендором).
Интеграция с отечественной экосистемой. Совместимость с российскими ОС (Astra, РЕД, ROSA), СУБД, средствами защиты (например, vGate) – упрощает внедрение единого импортозамещённого ландшафта.
Новые технологии под свои нужды. Реализация специфичных возможностей: работа без лицензий NVIDIA (FreeGRID), поддержка гостевых Windows без обращения к зарубежным серверам активации, отсутствие жёсткого вендорлока по железу (любое x86 подходит).
Стоимость и модель владения. Более низкая цена лицензий и поддержки по сравнению с VMware (особенно после удорожания VMware); оплата в рублях, отсутствие риска отключения при санкциях.
Минусы и вызовы:
Меньшая зрелость и удобство. Интерфейсы и процессы менее отточены – администрирование требует больше времени и знаний, некоторые задачи реализованы не так элегантно, больше ручной работы.
Ограниченная экосистема. Не все привычные внешние инструменты совместимы – придется пересматривать решения для бэкапа, мониторинга, а автоматизация требует дополнительных скриптов. Нет огромного сообщества интеграторов по всему миру, как у VMware.
Риски масштабируемости и багов. На больших нагрузках или в сложных сценариях могут всплывать проблемы, которые VMware уже давно решила. Требуется тщательное пилотирование и возможно компромиссы (уменьшить размер кластера, разделить на несколько и др.).
Обучение персонала. ИТ-специалистам, годами работавшим с VMware, нужно переучиваться. Нюансы каждой платформы свои, документация не всегда идеальна, на русском языке материалов меньше, чем англоязычных по VMware.
Отсутствие некоторых enterprise-фишек. Например, у VMware есть многолетние наработки по гибридному облаку, экосистема готовых решений в VMware Marketplace. Российским аналогам предстоит путь создания таких же богатых экосистем.
Таким образом, при функциональном паритете с VMware на бумаге, в практической эксплуатации российские продукты могут требовать больше усилий и доставлять больше проблем. Но этот разрыв постепенно сокращается по мере их развития и накопления опыта внедрений.
Выводы и перспективы импортозамещения VMware
За почти четыре года, прошедшие с ухода VMware, российская индустрия виртуализации совершила огромный рывок. Из десятков появившихся решений постепенно выделился костяк наиболее зрелых и универсальных продуктов, способных заменить VMware vSphere в корпоративных ИТ-инфраструктурах. Как показывают кейсы крупных организаций (банков, промышленных предприятий, госструктур), импортозамещение виртуализации в России – задача выполнимая, хотя и сопряжена с определёнными трудностями. Подводя итоги обзора, можно назвать наиболее перспективные платформы и технологии, на которые сегодня стоит обратить внимание ИТ-директорам:
SpaceVM + Space VDI (экоcистема Space) – комплексное решение от компании «ДАКОМ M», которое отличается максимальной полнотой функционала. SpaceVM обеспечивает производительную серверную виртуализацию с собственными технологиями (SDN, FreeGRID), а Space VDI дополняет её средствами виртуализации рабочих мест. Этот тандем особенно хорош для компаний, которым нужны все компоненты "как у VMware" под одним брендом – гипервизор, диспетчеры, клиенты, протоколы. Space активно набирает популярность: 1-е место в рейтингах, успешные внедрения, награды отрасли. Можно ожидать, что он станет одним из столпов корпоративной виртуализации РФ.
Basis Dynamix – продукт компании «Базис», ставший лидером технических рейтингов. Basis привлекает госзаказчиков и большие корпорации, ценящие интегрированный подход: платформа тесно сопряжена с отечественным оборудованием, ОС и имеет собственный центр разработки. Ее козыри – высокая производительность, гибкость (поддержка и классической, и HCI-схем) и готовность к кастомизации под клиента. Basis – хороший выбор для тех, кто строит полностью отечественный программно-аппаратный комплекс, и кому нужна платформа с длительной перспективой развития в России.
zVirt (Orion soft) – одна из самых распространённых на практике платформ, обладающая богатым набором функций и сильным акцентом на безопасность. За счет происхождения от oVirt, zVirt знаком многим по архитектуре, а доработки Orion soft сделали его удобнее и безопаснее (SDN, микросегментация, интеграция с vGate). Крупнейшая инсталляционная база говорит о доверии рынка. Хотя у zVirt есть ограничения по масштабированию, для средних размеров (десятки узлов) он отлично справляется. Это надежный вариант для постепенной миграции с VMware в тех организациях, где ценят проверенные решения и требуются сертификаты ФСТЭК по безопасности.
Red Виртуализация – решение от РЕД СОФТ, важное для госсектора и компаний с экосистемой РЕД ОС. Его выбрал, к примеру, Россельхозбанк для одной из крупнейших миграций в финансовом секторе. Продукт относительно консервативный (форк известного проекта), что можно считать плюсом – меньше сюрпризов, более понятный функционал. Red Virtualization перспективна там, где нужна максимальная совместимость с отечественным ПО (ПО РЕД, СУБД РЕД и пр.) и официальная поддержка на уровне регуляторов.
vStack HCP – хотя и более нишевое решение, но весьма перспективное для тех, кому нужна простота HCI и высочайшая производительность. Отсутствие зависимости от громоздких компонентов (ни Linux, ни Windows – гипервизор на FreeBSD) дает vStack определенные преимущества в легковесности. Его стоит рассматривать в том числе для задач на периферии, в распределенных офисах, где нужна автономная работа без сложной поддержки, или для быстрорастущих облачных сервисов, где горизонтальное масштабирование – ключевой фактор.
HostVM VDI / Veil / Termidesk – в сфере VDI помимо Space VDI, внимания заслуживают и другие разработки. HostVM VDI – как универсальный брокер с множеством протоколов – может подойти интеграторам, строящим сервис VDI для разных платформ. Veil VDI и Termidesk – пока чуть менее известны на рынке, но имеют интересные технологии (например, Termidesk с собственным кодеком TERA). Для компаний, уже использующих решения этих вендоров, логично присмотреться к их VDI для совместимости.
В заключение, можно уверенно сказать: российские продукты виртуализации достигли уровня, при котором ими можно заменить VMware vSphere во многих сценариях. Да, переход потребует усилий – от тестирования до обучения персонала, – но выгоды в виде независимости от внешних факторов, соответствия требованиям законодательства и поддержки со стороны локальных вендоров зачастую перевешивают временные сложности. Российские разработчики продемонстрировали способность быстро закрыть функциональные пробелы и даже внедрить новые инновации под нужды рынка. В ближайшие годы можно ожидать дальнейшего роста качества этих продуктов: уже сейчас виртуализация перестает быть "экзотикой" и становится обыденным, надёжным инструментом в руках отечественных ИТ-специалистов. А значит, корпоративный сектор России получает реальную альтернативу VMware – собственный технологический базис для развития ИТ-инфраструктуры.
Broadcom в сотрудничестве с Dell, Intel, NVIDIA и SuperMicro недавно продемонстрировала преимущества виртуализации, представив результаты MLPerf Inference v5.1. Платформа VMware Cloud Foundation (VCF) 9.0 показала производительность, сопоставимую с bare metal, по ключевым AI-бенчмаркам, включая Speech-to-Text (Whisper), Text-to-Video (Stable Diffusion XL), большие языковые модели (Llama 3.1-405B и Llama 2-70B), графовые нейронные сети (R-GAT) и компьютерное зрение (RetinaNet). Эти результаты были достигнуты как на GPU-, так и на CPU-решениях с использованием виртуализированных конфигураций NVIDIA с 8x H200 GPU, GPU 8x B200 в режиме passthrough/DirectPath I/O, а также виртуализированных двухсокетных процессоров Intel Xeon 6787P.
Для прямого сравнения соответствующих метрик смотрите официальные результаты MLCommons Inference 5.1. Этими результатами Broadcom вновь демонстрирует, что виртуализованные среды VCF обеспечивают производительность на уровне bare metal, позволяя заказчикам получать преимущества в виде повышенной гибкости, доступности и адаптивности, которые предоставляет VCF, при сохранении отличной производительности.
VMware Private AI — это архитектурный подход, который балансирует бизнес-выгоды от AI с требованиями организации к конфиденциальности и соответствию нормативам. Основанный на ведущей в отрасли платформе частного облака VMware Cloud Foundation (VCF), этот подход обеспечивает конфиденциальность и контроль данных, выбор между решениями с открытым исходным кодом и коммерческими AI-платформами, а также оптимальные затраты, производительность и соответствие требованиям.
Private AI позволяет предприятиям использовать широкий спектр AI-решений в своей среде — NVIDIA, AMD, Intel, проекты сообщества с открытым исходным кодом и независимых поставщиков программного обеспечения. С VMware Private AI компании могут развертывать решения с уверенностью, зная, что Broadcom выстроила партнерства с ведущими поставщиками AI-технологий. Broadcom добавляет мощь своих партнеров — Dell, Intel, NVIDIA и SuperMicro — в VCF, упрощая управление дата-центрами с AI-ускорением и обеспечивая эффективную разработку и выполнение приложений для ресурсоемких AI/ML-нагрузок.
В тестировании были показаны три конфигурации в VCF:
SuperMicro GPU SuperServer AS-4126GS-NBR-LCC с NVLink-соединенными 8x B200 в режиме DirectPath I/O
Dell PowerEdge XE9680 с NVLink-соединенными 8x H200 в режиме vGPU
Конфигурация 1-node-2S-GNR_86C_ESXi_172VCPU-VM с процессорами Intel® Xeon® 6787P с 86 ядрами.
Производительность MLPerf Inference 5.1 с VCF на сервере SuperMicro с NVIDIA 8x B200
VCF поддерживает как DirectPath I/O, так и технологии NVIDIA Virtual GPU (vGPU) для использования GPU в задачах AI и других GPU-ориентированных нагрузках. Для демонстрации AI-производительности с GPU NVIDIA B200 был выбран DirectPath I/O для бенчмаркинга MLPerf Inference.
Инженеры запускали нагрузки MLPerf Inference на сервере SuperMicro SuperServer AS-4126GS-NBR-LCC с восемью GPU NVIDIA SXM B200 с 180 ГБ HBM3e при использовании VCF 9.0.0.
В таблице ниже показаны аппаратные конфигурации, использованные для выполнения нагрузок MLPerf Inference 5.1 на bare metal и виртуализированных системах. Бенчмарки были оптимизированы с помощью NVIDIA TensorRT-LLM. TensorRT-LLM включает в себя компилятор глубокого обучения TensorRT и содержит оптимизированные ядра, этапы пред- и пост-обработки, а также примитивы меж-GPU и межузлового взаимодействия, обеспечивая выдающуюся производительность на GPU NVIDIA.
Параметр
Bare Metal
Виртуальная среда
Система
SuperMicro GPU SuperServer SYS-422GA-NBRT-LCC
SuperMicro GPU SuperServer AS-4126GS-NBR-LCC
Процессоры
2x Intel Xeon 6960P, 72 ядра
2x AMD EPYC 9965, 192 ядра
Логические процессоры
144
192 из 384 (50%) выделены виртуальной машине для инференса (при загрузке CPU менее 10%). Таким образом, 192 остаются доступными для других ВМ/нагрузок с полной изоляцией благодаря виртуализации
GPU
8x NVIDIA B200, 180 ГБ HBM3e
DirectPath I/O, 8x NVIDIA B200, 180 ГБ HBM3e
Межсоединение ускорителей
18x NVIDIA NVLink 5-го поколения, суммарная пропускная способность 14,4 ТБ/с
18x NVIDIA NVLink 5-го поколения, суммарная пропускная способность 14,4 ТБ/с
Память
2,3 ТБ
Память хоста — 3 ТБ, 2,5 ТБ выделено виртуальной машине для инференса
Хранилище
4x NVMe SSD по 15,36 ТБ
4x NVMe SSD по 13,97 ТБ
ОС
Ubuntu 24.04
ВМ Ubuntu 24.04 на VCF / ESXi 9.0.0.0.24755229
CUDA
CUDA 12.9 и драйвер 575.57.08
CUDA 12.8 и драйвер 570.158.01
TensorRT
TensorRT 10.11
TensorRT 10.11
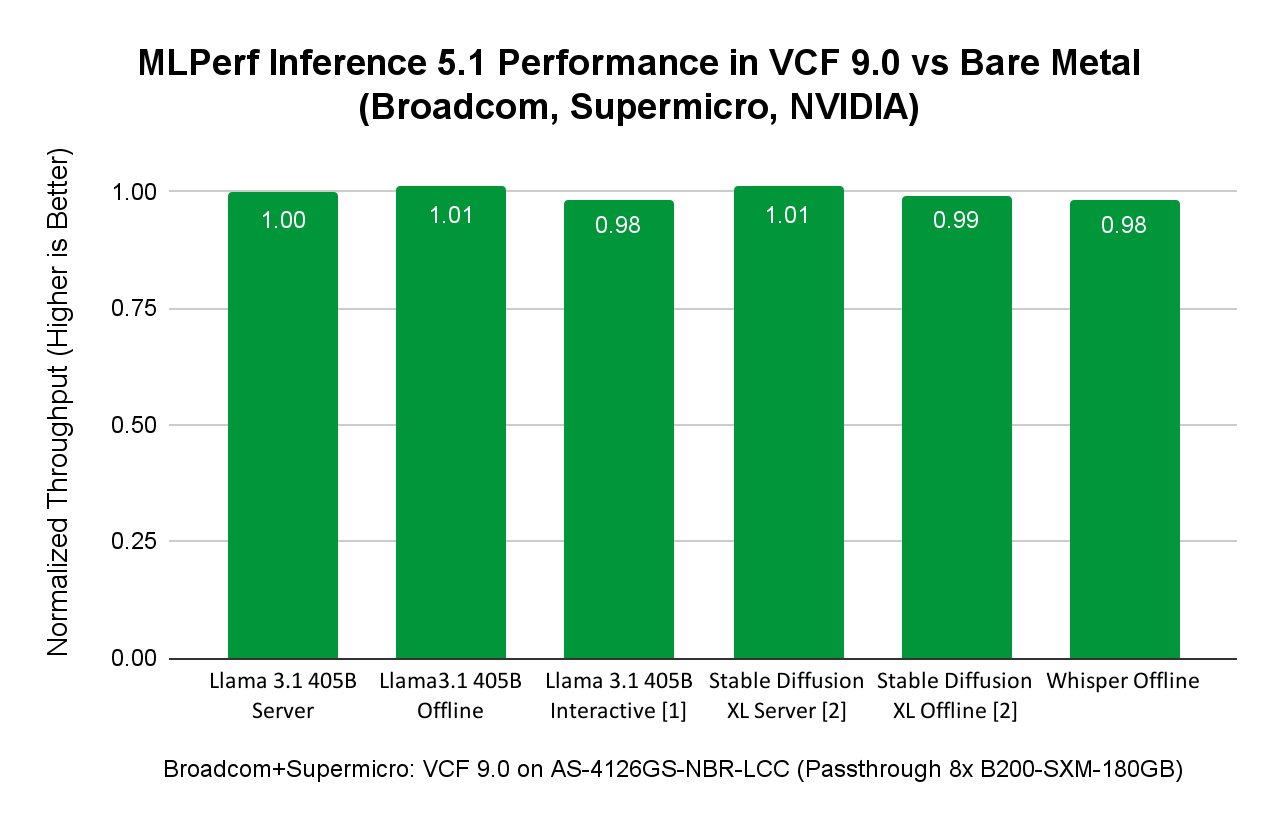
Сравнение производительности виртуализованных и bare metal ML/AI-нагрузок на примере сервера SuperMicro SuperServer AS-4126GS-NBR-LCC:
Некоторые моменты:
Результат сценария Llama 3.1 405B в интерактивном режиме не был верифицирован Ассоциацией MLCommons. Broadcom и SuperMicro не отправляли его на проверку, поскольку это не требовалось.
Результаты Stable Diffusion XL, представленные Broadcom и SuperMicro, не могли быть напрямую сопоставлены с результатами SuperMicro на том же оборудовании, поскольку SuperMicro не отправляла результаты бенчмарка Stable Diffusion на платформе bare metal. Поэтому сравнение выполнено с другой заявкой, использующей сопоставимый хост с 8x NVIDIA B200-SXM-180GB.
Рисунок выше показывает, что AI/ML-нагрузки инференса из различных доменов — LLM (Llama 3.1 с 405 млрд параметров), Speech-to-Text (Whisper от OpenAI) и Text-to-Image (Stable Diffusion XL) — в VCF достигают производительности, сопоставимой с bare metal. При запуске AI/ML-нагрузок в VCF пользователи получают преимущества управления датацентром, предоставляемые VCF, при сохранении производительности на уровне bare metal.
Производительность MLPerf Inference 5.1 с VCF на сервере Dell с NVIDIA 8x H200
Broadcom поддерживает корпоративных заказчиков, использующих AI-инфраструктуру от различных аппаратных вендоров. В рамках раунда заявок для MLPerf Inference 5.1, VMware совместно с NVIDIA и Dell продемонстрировала VCF 9.0 как отличную платформу для AI-нагрузок, особенно для генеративного AI. Для бенчмаркинга был выбран режим vGPU, чтобы показать еще один вариант развертывания, доступный заказчикам в VCF 9.0.
Функциональность vGPU, интегрированная с VCF, предоставляет ряд преимуществ для развертывания и управления AI-инфраструктурой. Во-первых, VCF формирует группы устройств из 2, 4 или 8 GPU с использованием NVLink и NVSwitch. Эти группы могут выделяться различным виртуальным машинам, обеспечивая гибкость распределения GPU-ресурсов в соответствии с требованиями нагрузок и повышая утилизацию GPU.
Во-вторых, vGPU позволяет нескольким виртуальным машинам совместно использовать GPU-ресурсы на одном хосте. Каждой ВМ выделяется часть памяти GPU и/или вычислительных ресурсов GPU в соответствии с профилем vGPU. Это дает возможность нескольким небольшим нагрузкам совместно использовать один GPU, исходя из их требований к памяти и вычислениям, что повышает плотность консолидации, максимизирует использование ресурсов и снижает затраты на развертывание AI-инфраструктуры.
В-третьих, vGPU обеспечивает гибкое управление дата-центрами с GPU, поддерживая приостановку/возобновление работы виртуальных машин и VMware vMotion (примечание: vMotion поддерживается только в том случае, если AI-нагрузки не используют функцию Unified Virtual Memory GPU).
И наконец, vGPU позволяет различным GPU-ориентированным нагрузкам (таким как AI, графика или другие высокопроизводительные вычисления) совместно использовать одни и те же физические GPU, при этом каждая нагрузка может быть развернута в отдельной гостевой операционной системе и принадлежать разным арендаторам в мультиарендной среде.
VMware запускала нагрузки MLPerf Inference 5.1 на сервере Dell PowerEdge XE9680 с восемью GPU NVIDIA SXM H200 с 141 ГБ HBM3e при использовании VCF 9.0.0. Виртуальным машинам в тестах была выделена лишь часть ресурсов bare metal. В таблице ниже представлены аппаратные конфигурации, использованные для выполнения нагрузок MLPerf Inference 5.1 на системах bare metal и в виртуализированной среде.
Аппаратное и программное обеспечение для Dell PowerEdge XE9680:
Параметр
Bare Metal
Виртуальная среда
Система
Dell PowerEdge XE9680
Dell PowerEdge XE9680
Процессоры
Intel Xeon Platinum 8568Y+, 96 ядер
Intel Xeon Platinum 8568Y+, 96 ядер
Логические процессоры
192
Всего 192, 48 (25%) выделены виртуальной машине для инференса, 144 доступны для других ВМ/нагрузок с полной изоляцией благодаря виртуализации
Память хоста — 3 ТБ, 2 ТБ (67%) выделено виртуальной машине для инференса
Хранилище
2 ТБ SSD, 5 ТБ CIFS
2x SSD по 3,5 ТБ, 1x SSD на 7 ТБ
ОС
Ubuntu 24.04
ВМ Ubuntu 24.04 на VCF / ESXi 9.0.0.0.24755229
CUDA
CUDA 12.8 и драйвер 570.133
CUDA 12.8 и драйвер Linux 570.158.01
TensorRT
TensorRT 10.11
TensorRT 10.11
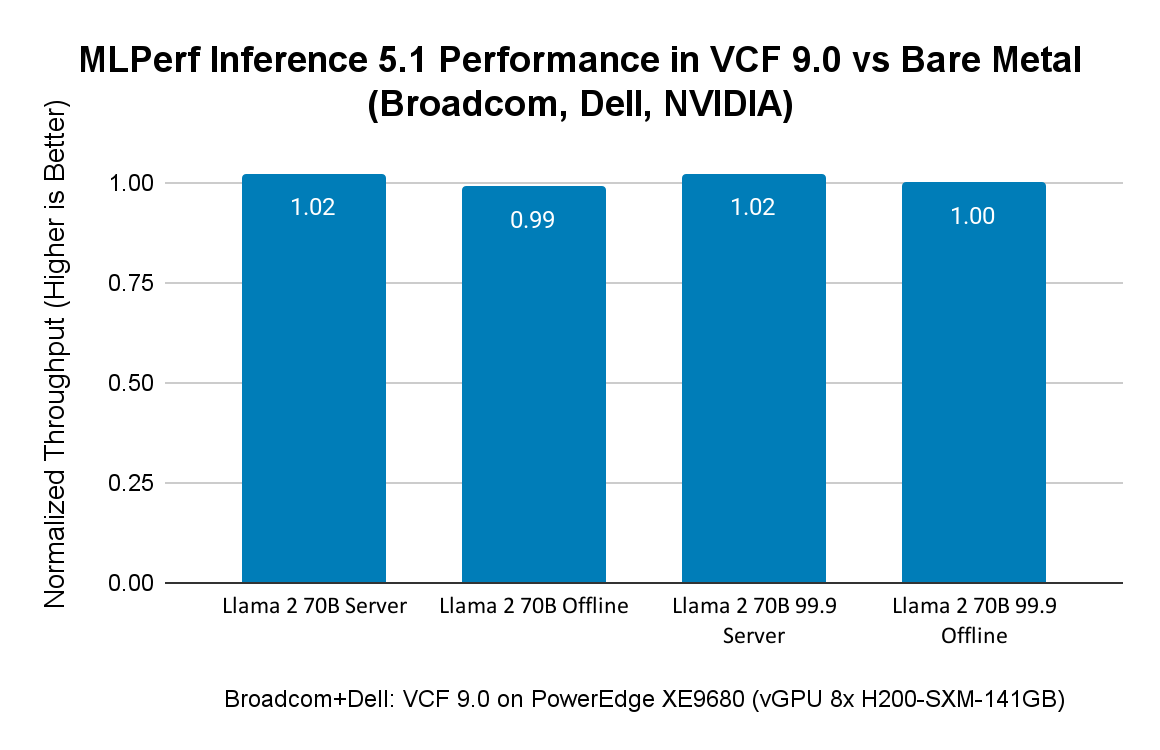
Результаты MLPerf Inference 5.1, представленные в таблице, демонстрируют высокую производительность для больших языковых моделей (Llama 3.1 405B и Llama 2 70B), а также для задач генерации изображений (SDXL — Stable Diffusion).
Результаты MLPerf Inference 5.1 при использовании 8x vGPU в VCF 9.0 на аппаратной платформе Dell PowerEdge XE9680 с 8x GPU NVIDIA H200:
Бенчмарки
Пропускная способность
Llama 3.1 405B Server (токенов/с)
277
Llama 3.1 405B Offline (токенов/с)
547
Llama 2 70B Server (токенов/с)
33 385
Llama 2 70B Offline (токенов/с)
34 301
Llama 2 70B — высокая точность — Server (токенов/с)
33 371
Llama 2 70B — высокая точность — Offline (токенов/с)
34 486
SDXL Server (сэмплов/с)
17,95
SDXL Offline (сэмплов/с)
18,64
На рисунке ниже сравниваются результаты MLPerf Inference 5.1 в VCF с результатами Dell на bare metal на том же сервере Dell PowerEdge XE9680 с GPU H200. Результаты как Broadcom, так и Dell находятся в открытом доступе на сайте MLCommons. Поскольку Dell представила только результаты для Llama 2 70B, на рисунке 2 показано сравнение производительности MLPerf Inference 5.1 в VCF 9.0 и на bare metal именно для этих нагрузок. Диаграмма демонстрирует, что разница в производительности между VCF и bare metal составляет всего 1–2%.
Сравнение производительности виртуализированных и bare metal ML/AI-нагрузок на Dell XE9680 с 8x GPU H200 SXM 141 ГБ:
Производительность MLPerf Inference 5.1 в VCF с процессорами Intel Xeon 6-го поколения
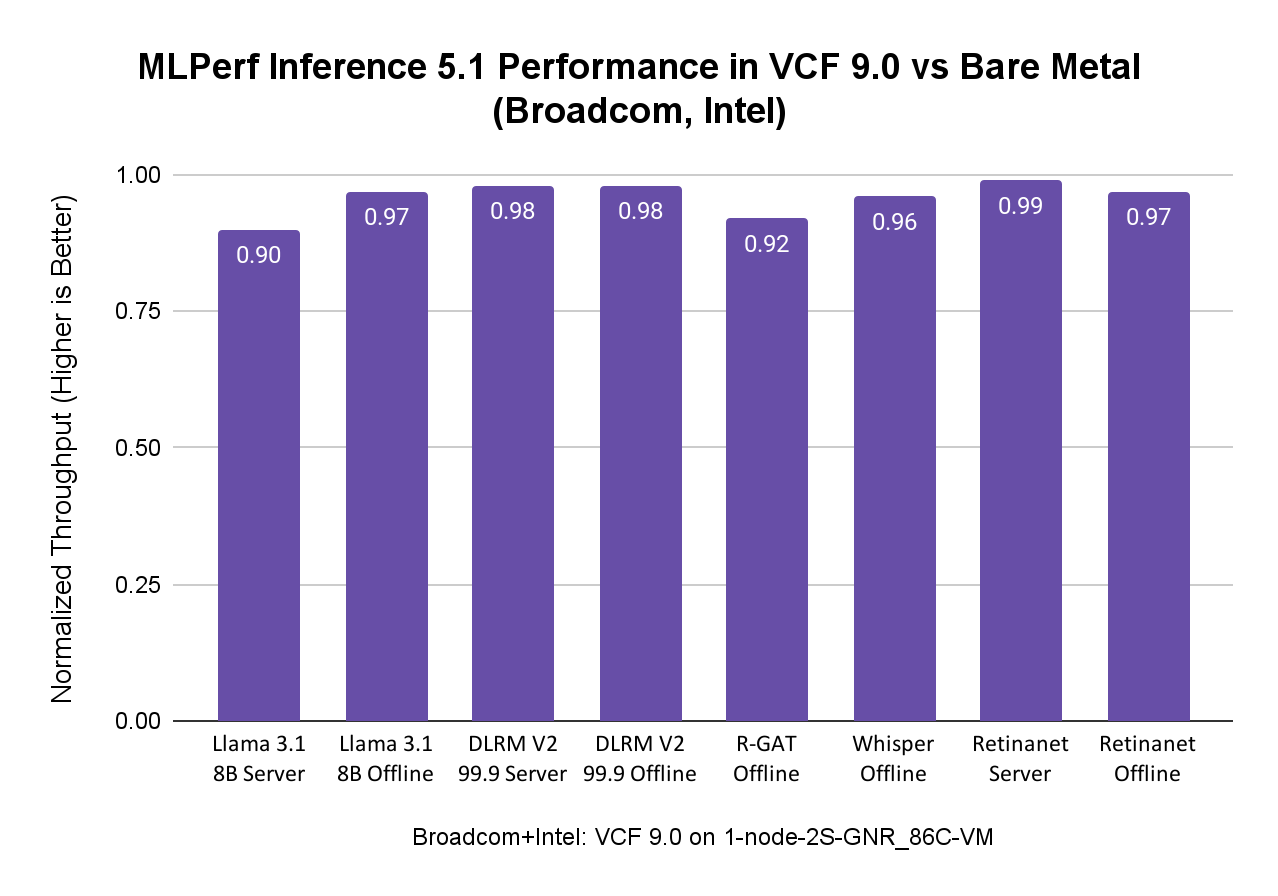
Intel и Broadcom совместно продемонстрировали возможности VCF, ориентированные на заказчиков, использующих исключительно процессоры Intel Xeon со встроенным ускорением AMX для AI-нагрузок. В тестах запускали нагрузки MLPerf Inference 5.1, включая Llama 3.1 8B, DLRM-V2, R-GAT, Whisper и RetinaNet, на системе, представленной в таблице ниже.
Аппаратное и программное обеспечение для систем Intel
AI-нагрузки, особенно модели меньшего размера, могут эффективно выполняться на процессорах Intel Xeon с ускорением AMX в среде VCF, достигая производительности, близкой к bare metal, и одновременно получая преимущества управляемости и гибкости VCF. Это делает процессоры Intel Xeon отличной отправной точкой для организаций, начинающих свой путь в области AI, поскольку они могут использовать уже имеющуюся инфраструктуру.
Результаты MLPerf Inference 5.1 при использовании процессоров Intel Xeon в VCF показывают производительность на уровне bare metal. В сценариях, где в датацентре отсутствуют ускорители, такие как GPU, или когда AI-нагрузки менее вычислительно требовательны, в зависимости от задач заказчика, AI/ML-нагрузки могут быть развернуты на процессорах Intel Xeon в VCF с преимуществами виртуализации и при сохранении производительности на уровне bare metal, как показано на рисунке ниже:
Бенчмарки MLPerf Inference
Каждый бенчмарк определяется набором данных (Dataset) и целевым уровнем качества (Quality Target). В следующей таблице приведено краткое описание бенчмарков, входящих в данную версию набора тестов (официальные правила остаются первоисточником):
В сценарии Offline генератор нагрузки (LoadGen) отправляет все запросы в тестируемую систему (SUT) в самом начале прогона. В сценарии Server LoadGen отправляет новые запросы в SUT в соответствии с распределением Пуассона. Это показано в таблице ниже.
Сценарии тестирования MLPerf Inference:
Сценарий
Генерация запросов
Длительность
Сэмплов на запрос
Ограничение по задержке
Tail latency
Метрика производительности
Server
LoadGen отправляет новые запросы в SUT согласно распределению Пуассона
270 336 запросов и 60 секунд
1
Зависит от бенчмарка
99%
Максимально поддерживаемый параметр пропускной способности Пуассона
VCF предоставляет заказчикам несколько гибких вариантов развертывания AI-инфраструктуры, поддерживает оборудование от различных вендоров и позволяет использовать разные подходы к запуску AI-нагрузок, применяющих как GPU, так и CPU для вычислений.
При использовании GPU виртуализированные конфигурации виртуальных машин в наших бенчмарках задействуют лишь часть ресурсов CPU и памяти, при этом обеспечивая производительность MLPerf Inference 5.1 на уровне bare metal даже при пиковом использовании GPU — это одно из ключевых преимуществ виртуализации. Такой подход позволяет задействовать оставшиеся ресурсы CPU и памяти для выполнения других нагрузок с полной изоляцией, снизить стоимость AI/ML-инфраструктуры и использовать преимущества виртуализации VCF при управлении датацентрами.
Результаты бенчмарков показывают, что VCF 9.0 находится в «зоне Златовласки» для AI/ML-нагрузок, обеспечивая производительность, сопоставимую с bare metal. VCF также упрощает управление и быструю обработку нагрузок благодаря использованию vGPU, гибких NVLink-соединений между устройствами и технологий виртуализации, позволяющих применять AI/ML-инфраструктуру для графики, обучения и инференса. Виртуализация снижает совокупную стоимость владения (TCO) AI/ML-инфраструктурой, обеспечивая совместное использование дорогостоящих аппаратных ресурсов несколькими арендаторами.
VMware vCenter Converter – это классический инструмент VMware для перевода физических и виртуальных систем в формат виртуальных машин VMware. Его корни уходят к утилите VMware P2V Assistant, которая существовала в 2000-х годах для «Physical-to-Virtual» миграций. В 2007 году VMware выпустила первую версию Converter (3.0), заменив P2V Assistant...
vSAN File Services — это встроенная в vSAN опциональная функция, которая позволяет организовать файловые расшаренные ресурсы (файловые шары) прямо «поверх» кластера vSAN. То есть, вместо покупки отдельного NAS-массива или развертывания виртуальных машин-файловых серверов, можно просто включить эту службу на уровне кластера.
После включения vSAN File Services становится возможным предоставить SMB-шары (для Windows-систем) и/или NFS-экспорты (для Linux-систем и cloud-native приложений) прямо из vSAN.
Основные возможности и сильные стороны
Вот ключевые функции и плюсы vSAN File Services:
Возможность / свойство
Что это даёт / когда полезно
Поддержка SMB и NFS (v3 / v4.1)
Можно обслуживать и Windows, и Linux / контейнерные среды. vSAN превращается не только в блочное хранилище для виртуальных машин, но и в файловое для приложений и пользователей.
Файл-сервисы без отдельного «файлера»
Нет нужды покупать, настраивать и поддерживать отдельный NAS или физическое устройство — экономия затрат и упрощение инфраструктуры.
Лёгкость включения и управления (через vSphere Client)
Администратор активирует службу через привычный интерфейс, не требуются отдельные системы управления.
До 500 файловых шар на кластер (и до 100 SMB-шар)
Подходит для сравнительно крупных сред, где нужно много шар для разных подразделений, проектов, контейнеров и другого.
Распределение нагрузки и масштабируемость
Служба развёрнута через набор «протокол-сервисов» (контейнеры / агенты), которые равномерно размещаются по хостам; данные шар распределяются как vSAN-объекты — нагрузка распределена, масштабирование (добавление хостов / дисков) + производительность + отказоустойчивость.
Интегрированная файловая система (VDFS)
Это не просто «виртуальные машины + samba/ganesha» — vSAN использует собственную распределённую FS, оптимизированную для работы как файловое хранилище, с балансировкой, метаданными, шардированием и управлением через vSAN.
Мониторинг, отчёты, квоты, ABE-контроль доступа
Как и для виртуальных машин, для файловых шар есть метрики (IOPS, latency, throughput), отчёты по использованию пространства, возможность задать квоты, ограничить видимость папок через ABE (Access-Based Enumeration) для SMB.
Поддержка небольших кластеров / 2-node / edge / remote sites
Можно применять даже на «граничных» площадках, филиалах, удалённых офисах — где нет смысла ставить полноценный NAS.
Когда / кому это может быть особенно полезно
vSAN File Services может быть выгоден для:
Организаций, которые уже используют vSAN и хотят минимизировать аппаратное разнообразие — делать и виртуальные машины, и файловые шары на одной платформе.
Виртуальных сред (от средних до крупных), где нужно предоставить множество файловых шар для пользователей, виртуальных машин, контейнеров, облачных приложений.
Сценариев с контейнерами / cloud-native приложениями, где требуется RWX (Read-Write-Many) хранилище, общие папки, persistent volumes — все это дают NFS-шары от vSAN.
Удалённых офисов, филиалов, edge / branch-site, где нет смысла ставить отдельное файловое хранилище.
Случаев, когда хочется централизованного управления, мониторинга, политики хранения и квот — чтобы всё хранилище было в рамках одного vSAN-кластера.
Ограничения и моменты, на которые нужно обратить внимание
Нужно учитывать следующие моменты при планировании использования:
Требуется выделить отдельные IP-адреса для контейнеров, которые предоставляют шары, плюс требуется настройка сети (promiscuous mode, forged transmits).
Нельзя использовать одну и ту же шару одновременно и как SMB, и как NFS.
vSAN File Services не предназначен для создания NFS датасторов, на которые будут смонтированы хосты ESXi и запускаться виртуальные машины — только файловые шары для сервисов/гостевых систем.
Если требуется репликация содержимого файловых шар — её нужно организовывать вручную (например, средствами операционной системы или приложений), так как vSAN File Services не предлагает встроенной гео-репликации.
При кастомной и сложной сетевой архитектуре (например, stretched-кластер) — рекомендуется внимательно проектировать размещение контейнеров, IP-адресов, маршрутизации и правил site-affinity.
Технические выводы для администратора vSAN
Если вы уже используете vSAN — vSAN File Services даёт возможность расширить функциональность хранения до полноценного файлового — без дополнительного железа и без отдельного файлера.
Это удобно для унификации: блочное + файловое хранение + облачные/контейнерные нагрузки — всё внутри vSAN.
Управление и мониторинг централизованы: через vSphere Client/vCenter, с известными инструментами, что снижает операционную сложность.
Подходит для «гибридных» сценариев: Windows + Linux + контейнеры, централизованные файлы, общие репозитории, home-директории, данные для приложений.
Можно использовать в небольших и распределённых средах — филиалы, edge, remote-офисы — с минимальным оверхэдом.
Diagnostics for VMware Cloud Foundation — это централизованная платформа, которая отслеживает общее состояние работы программного стека VMware Cloud Foundation (VCF). Это платформа самообслуживания, помогающая анализировать и устранять неполадки компонентов VMware Cloud Foundation, включая vCenter, ESX, vSAN, а также возможностей, таких как vSphere vMotion, снапшоты, развертывание виртуальных машин (VM provisioning), и других аспектов, включая уведомления безопасности и сертификаты. Администратор инфраструктуры может использовать диагностические данные, чтобы контролировать текущее состояние своей среды.
Диагностические результаты (Findings)
Результаты диагностики, которые ранее предоставлялись через Skyline Advisor и Skyline Health Diagnostics, теперь доступны клиентам VCF и vSphere Foundation (VVF) в рамках продукта VCF Operations. Результаты приоритизируются по:
Часто встречающимся проблемам, выявленным службой технической поддержки Broadcom.
Вопросам, поднятым в рамках анализа эскалаций (post escalation review).
В последнем релизе VCF Operations выпущено 114 новых диагностических результатов (Findings):
83 — основаны на часто встречающихся проблемах.
15 — по результатам анализа эскалаций.
14 — связаны с уязвимостями безопасности (VMSA).
2 — по запросам клиентов.
Из них:
62 результата состояния (Health Findings) — эквивалентны результатам Skyline Advisor и автоматически проверяются каждые 4 часа.
52 результата на основе логов (Log-based Findings) — эквивалентны Skyline Health Diagnostics и инициируются вручную через интерфейс конфигурации.
Эти новые находки включены в VCF Operations 9.0.1 (Release Notes). Давайте посмотрим на некоторые примеры этих результатов.
Уязвимости безопасности
В VMSA-2025-0010 описана уязвимость аутентифицированного выполнения команд в VMware vCenter Server (CVE-2025-41225) и уязвимость межсайтового скриптинга (XSS) в VMware ESXi и vCenter Server (CVE-2025-41228). Злоумышленник, обладающий привилегиями для создания или изменения тревог (alarms) и выполнения действий сценариев (script action), может воспользоваться данной уязвимостью для выполнения произвольных команд на сервере vCenter.
Злоумышленник, имеющий сетевой доступ к странице входа определённого хоста ESX или к путям URL сервера vCenter Server, может использовать эту уязвимость для кражи cookie-файлов или перенаправления пользователей на вредоносные веб-сайты. Эта уязвимость устранена в vCenter Server 8.0 Update 3e.
Анализ после эскалации (Post Escalation Review)
Техническая поддержка Broadcom внедрила процесс Post Escalation Review, в рамках которого критические обращения анализируются для предотвращения подобных инцидентов в будущем. Одним из результатов такого анализа является создание новых диагностических результатов.
Хосты ESX могут терять подключение к vCenter из-за чрезмерной скорости логирования, что приводит к потере сообщений syslog и невозможности записи сервисных логов. Часто проблема наблюдается при включении дополнительного логирования NSX, когда файл dfwpktlogs.log превышает допустимую скорость записи syslog. Однако причиной может быть и любая другая служба, создающая чрезмерный объём логов. Данный результат отображается при появлении соответствующих сообщений в vmkernel.log на хосте ESX.
На хостах ESXi 8.0.2 и 8.0.3 фиксируются предупреждения “Miss counters detected” для драйверов Mellanox с ошибкой
nmlx5_QueryNicVportContext:188 command failed: IO was aborted.
Это известная ошибка в механизме проверки состояния драйвера, при которой NIC ошибочно определяется как неисправный. Исправлено в ESX 8.0 Update 3e (драйвер nmlx5 версии 4.23.6.5).
Во время выполнения VCF Operations for Logs Query хост ESX сообщает о состоянии Permanent Device Loss (PDL). В Storage View хранилище отображается как недоступное, а адаптер сообщает об утере связи с устройством (Lost Communication). Все пути к устройству помечаются как «мертвые» (All Paths Down, APD). В результате невозможно подключиться к хосту через vSphere Client, и хост отображается как Disconnected в vCenter. Данный результат фиксируется при обнаружении соответствующих сообщений в vmkernel.log.
Главная цель команды Diagnostics — удовлетворённость клиентов. VMware стремится защитить их инфраструктуру, предоставляя результаты, основанные на опыте работы службы поддержки Broadcom, также принимаются предложения и от пользователей.
На узлах vSAN происходит PSOD (Purple Screen of Death) из-за «зависших» операций ввода-вывода после сбоя диска. Команда ввода-вывода помечается как «застрявшая», а когда она завершается, соответствующие объекты уже освобождены, что вызывает сбой. Исправлено в ESX 8.0 Update 3e.
Чтобы ознакомиться со всеми диагностическими результатами в Diagnostics for VMware Cloud Foundation, откройте Findings Catalog в разделе Diagnostics Findings интерфейса VCF Operations. Для получения актуальных обновлений подпишитесь на Diagnostics for VMware Cloud Foundation Findings KB — он обновляется при каждом выпуске нового пакета или обновлении встроенных диагностических данных.
Команда поддержки VMware в Broadcom полностью привержена тому, чтобы помочь клиентам в процессе обновлений. Поскольку дата окончания общего срока поддержки VMware vSphere 7 наступила 2 октября 2025 года, многие пользователи обращаются к вендору в поисках лучших практик и пошаговых руководств по обновлению. И на этот раз речь идет не только об обновлениях с VMware vSphere 7 до VMware vSphere 8. Наблюдается активный рост подготовки клиентов к миграции с vSphere 7 на VMware Cloud Foundation (VCF) 9.0.
Планирование и выполнение обновлений может вызывать стресс, поэтому в VMware решили, что новый набор инструментов для обновления будет полезен клиентам. Чтобы сделать процесс максимально гладким, техническая команда VMware подготовила полезные ресурсы для подготовки к апгрейдам, которые помогут обеспечить миграцию инфраструктуры без серьезных проблем.
Чтобы помочь в этом процессе, каким бы он ни был, были подготовлены руководства в формате статей базы знаний (KB), которые проведут вас через весь процесс от начала до конца. Этот широкий набор статей базы знаний по обновлениям продуктов предоставляет простые, пошаговые инструкции по процессу обновления, выделяя области, требующие особого внимания, на каждом из следующих этапов:
Подготовка к обновлению
Последовательность и порядок выполнения апгрейда
Необходимые действия после переезда и миграции
Ниже приведен набор статей базы знаний об обновлениях, с которым настоятельно рекомендуется ознакомиться до проведения обновления инфраструктуры vSphere и других компонентов платформы VCF.
В современных ИТ-системах шифрование данных стало обязательным элементом защиты информации. Цель шифрования — гарантировать, что данные могут прочитать только системы, обладающие нужными криптографическими ключами. Любой, не имеющий ключей доступа, увидит лишь бессмысленный набор символов, поскольку информация надёжно зашифрована устойчивым алгоритмом AES-256. VMware vSAN поддерживает два уровня шифрования для повышения безопасности кластерного хранения данных: шифрование данных на носителях (Data-at-Rest Encryption) и шифрование данных при передаче (Data-in-Transit Encryption). Эти механизмы позволяют защитить данные как в состоянии покоя (на дисках), так и в движении (между узлами кластера). В результате vSAN помогает организациям соответствовать требованиям регуляторов и предотвращать несанкционированный доступ к данным, например, при краже носителей или перехвате сетевого трафика.
Архитектура шифрования vSAN включает несколько ключевых элементов: внешний или встроенный сервер управления ключами (KMS), сервер VMware vCenter, гипервизоры ESXi в составе vSAN-кластера и собственно криптографические модули в ядре гипервизора. Внешний KMS-сервер (совместимый с протоколом KMIP), либо встроенный поставщик ключей vSphere NKP, обеспечивает генерацию и хранение мастер-ключей шифрования. vCenter Server отвечает за интеграцию с KMS: именно vCenter устанавливает доверенные отношения (обмен сертификатами) с сервером ключей и координирует выдачу ключей хостам ESXi. Каждый узел ESXi, входящий в шифрованный кластер vSAN, содержит встроенный криптомодуль VMkernel (сертифицированный по требованиям FIPS), который выполняет операции шифрования и дешифрования данных на стороне гипервизора.
Распределение ключей
При включении шифрования vSAN на кластере vCenter запрашивает у KMS два ключа для данного кластера: ключ шифрования ключей (Key Encryption Key, KEK) и ключ хоста (Host Key). KEK играет роль мастер-ключа: с его помощью будут шифроваться все остальные ключи (например, ключи данных). Host Key предназначен для защиты дампов памяти (core dumps) и других служебных данных хоста. После получения этих ключей vCenter передаёт информацию о KMS и идентификаторы ключей (ID) всем хостам кластера. Каждый узел ESXi устанавливает прямое соединение с KMS (по протоколу KMIP) и получает актуальные копии KEK и Host Key, помещая их в защищённый кэш памяти.
Важно: сами ключи не сохраняются на диске хоста, они хранятся только в оперативной памяти или, при наличии, в аппаратном модуле TPM на узле. Это означает, что при перезагрузке хоста ключи стираются из памяти и в общем случае должны быть вновь запрошены у KMS, прежде чем хост сможет монтировать зашифрованное хранилище.
Ключи данных (DEK)
Помимо вышеупомянутых кластерных ключей, каждый диск или объект данных получает свой собственный ключ шифрования данных (Data Encryption Key, DEK). В оригинальной архитектуре хранения vSAN (OSA) гипервизор генерирует уникальный DEK (алгоритм XTS-AES-256) для каждого физического диска в дисковой группе. Эти ключи оборачиваются (wrap) с помощью кластерного KEK и сохраняются в метаданных, что позволяет безопасно хранить ключи на дисках: получить «сырой» DEK можно только расшифровав его при помощи KEK. В более новой архитектуре vSAN ESA подход несколько отличается: используется единый ключ шифрования кластера, но при этом для различных объектов данных применяются уникальные производные ключи. Благодаря этому данные каждой виртуальной машины шифруются своим ключом, даже если в основе лежит общий кластерный ключ. В обоих случаях vSAN обеспечивает надёжную защиту: компрометация одного ключа не даст злоумышленнику доступа ко всему массиву данных.
Роль гипервизора и производительность
Шифрование в vSAN реализовано на уровне ядра ESXi, то есть прозрачно для виртуальных машин. Гипервизор использует сертифицированный криптографический модуль VMkernel, прошедший все необходимые проверки по стандарту FIPS 140-2 (а в новых версиях — и FIPS 140-3). Все операции шифрования выполняются с использованием аппаратного ускорения AES-NI, что минимизирует влияние на производительность системы. Опыт показывает, что нагрузка на CPU и задержки ввода-вывода при включении шифрования vSAN обычно незначительны и хорошо масштабируются с ростом числа ядер и современных процессоров. В свежей архитектуре ESA эффективность ещё выше: благодаря более оптимальному расположению слоя шифрования в стеке vSAN, для той же нагрузки требуется меньше CPU-циклов и операций, чем в классической архитектуре OSA.
Управление доступом
Стоит упомянуть, что управление шифрованием в vSAN встроено в систему ролей и привилегий vCenter. Только пользователи с особыми правами (Cryptographic administrator) могут настраивать KMS и включать/отключать шифрование на кластере. Это добавляет дополнительный уровень безопасности: случайный администратор без соответствующих привилегий даже не увидит опцию включения шифрования в интерфейсе. Разграничение доступа гарантирует, что ключи шифрования и связанные операции контролируются ограниченным кругом доверенных администраторов.
Шифрование данных на носителях (vSAN Data-at-Rest Encryption)
Этот тип шифрования обеспечивает защиту всех данных, хранящихся в vSAN-датасторе. Включение функции означает, что вся информация, записываемая на диски кластера, автоматически шифруется на последнем этапе ввода-вывода перед сохранением на устройство. При чтении данные расшифровываются гипервизором прозрачно для виртуальных машин – приложения и ОС внутри ВМ не осведомлены о том, что данные шифруются. Главное назначение Data-at-Rest Encryption – обезопасить данные на случай, если накопитель будет изъят из системы (например, при краже или некорректной утилизации дисков).
Без соответствующих ключей злоумышленник не сможет прочитать информацию с отключенного от кластера диска. Шифрование «на покое» не требует специальных самошифрующихся дисков – vSAN осуществляет его программно, используя собственные криптомодули, и совместимо как с гибридными, так и полностью флэш-конфигурациями хранилища.
Принцип работы: в оригинальной реализации OSA шифрование данных происходит после всех операций дедупликации и сжатия, то есть уже на «выходе» перед записью на носитель. Такой подход позволяет сохранить эффективность экономии места: данные сначала сжимаются и устраняются дубликаты, и лишь затем шифруются, благодаря чему коэффициенты дедупликации/сжатия не страдают. В архитектуре ESA шифрование интегрировано выше по стеку – на уровне кэша – но всё равно после выполнения компрессии данных.
То есть в ESA шифрование также не препятствует сжатию. Однако особенностью ESA является то, что все данные, покидающие узел, уже зашифрованы высокоуровневым ключом кластера (что частично перекрывает и трафик между узлами – см. ниже). Тем не менее для обеспечения максимальной криптостойкости vSAN ESA по-прежнему поддерживает отдельный механизм Data-in-Transit Encryption для уникального шифрования каждого сетевого пакета.
Включение и поддержка: шифрование данных на носителях включается на уровне всего кластера vSAN – достаточно установить флажок «Data-at-Rest Encryption» в настройках служб vSAN для выбранного кластера. Данная возможность доступна только при наличии лицензии vSAN Enterprise или выше.
В традиционной архитектуре OSA шифрование можно включать как при создании нового кластера, так и на уже работающем кластере. В последнем случае vSAN выполнит поочерёдное перевоспроизведение данных с каждого диска (evacuation) и форматирование дисковых групп в зашифрованном виде, что потребует определённых затрат ресурсов и времени. В архитектуре ESA, напротив, решение о шифровании принимается только на этапе создания кластера и не может быть изменено позднее без полной перестройки хранилища. Это связано с тем, что в ESA шифрование глубоко интегрировано в работу кластера, обеспечивая максимальную производительность, но и требуя фиксации режима на старте. В обоих случаях, после включения, сервис шифрования прозрачно работает со всеми остальными функциями vSAN (в том числе со снапшотами, клонированием, vMotion и т.д.) и практически не влияет на операционную деятельность кластера.
Шифрование данных при передаче (vSAN Data-in-Transit Encryption)
Второй компонент системы безопасности vSAN – это шифрование сетевого трафика между узлами хранения. Функция Data-in-Transit Encryption гарантирует, что все данные, пересылаемые по сети между хостами vSAN, будут зашифрованы средствами гипервизора.
Это особенно важно, если сеть хранения не полностью изолирована или если требуется соответствовать строгим стандартам по защите данных в транзите. Механизм шифрования трафика не требует KMS: при включении этой опции хосты vSAN самостоятельно генерируют и обмениваются симметричными ключами для установления защищённых каналов. Процесс полностью автоматизирован и не требует участия администратора – достаточно активировать настройку в параметрах кластера.
Data-in-Transit Encryption впервые появилась в vSAN 7 Update 1 и доступна для кластеров как с OSA, так и с ESA. В случае OSA администратор может независимо включить шифрование трафика (оно не зависит от шифрования на дисках, но для полноты защиты желательно задействовать оба механизма). В случае ESA отдельного переключателя может не потребоваться: при создании кластера с шифрованием данные «на лету» фактически уже будут выходить из узлов зашифрованными единым высокоуровневым ключом. Однако, чтобы каждый сетевой пакет имел уникальный криптографический отпечаток, ESA по-прежнему предусматривает опцию Data-in-Transit (она остаётся активной в интерфейсе и при включении обеспечит дополнительную уникализацию шифрования каждого пакета). Следует учесть, что на момент выпуска vSAN 9.0 в составе VCF 9.0 шифрование трафика поддерживается только для обычных (HCI) кластеров vSAN и недоступно для т. н. disaggregated (выделенных storage-only) кластеров.
С технической точки зрения, Data-in-Transit Encryption использует те же проверенные криптомодули, сертифицированные по FIPS 140-2/3, что и шифрование данных на дисках. При активации этой функции vSAN автоматически выполняет взаимную аутентификацию хостов и устанавливает между ними защищённые сессии с помощью динамически создаваемых ключей. Когда новый узел присоединяется к шифрованному кластеру, для него генерируются необходимые ключи и он аутентифицируется существующими участниками; при исключении узла его ключи отзываются, и трафик больше не шифруется для него. Всё это происходит «под капотом», не требуя ручной настройки. В результате даже при потенциальном перехвате пакетов vSAN-трафика на уровне сети, извлечь из них полезные данные не представляется возможным.
Для использования шифрования данных на vSAN необходим сервер управления ключами (Key Management Server, KMS), совместимый со стандартом KMIP 1.1+. Исключение составляет вариант применения встроенного поставщика ключей vSphere (Native Key Provider, NKP), который появился начиная с vSphere 7.0 U2. Внешний KMS может быть программным или аппаратным (множество сторонних решений сертифицировано для работы с vSAN), но в любом случае требуется лицензия не ниже vSAN Enterprise.
Перед включением шифрования администратор должен зарегистрировать KMS в настройках vCenter: добавить информацию о сервере и установить доверие между vCenter и KMS. Обычно настройка доверия реализуется через обмен сертификатами: vCenter либо получает от KMS корневой сертификат (Root CA) для проверки подлинности, либо отправляет на KMS сгенерированный им запрос на сертификат (CSR) для подписи. В результате KMS и vCenter обмениваются удостоверяющими сертификатами и устанавливают защищённый канал. После этого vCenter может выступать клиентом KMS и запрашивать ключи.
В конфигурации с Native Key Provider процесс ещё проще: NKP разворачивается непосредственно в vCenter, генерируя мастер-ключ локально, поэтому внешний сервер не нужен. Однако даже в этом случае рекомендуется экспортировать (зарезервировать) копию ключа NKP во внешнее безопасное место, чтобы избежать потери ключей в случае сбоя vCenter.
Запрос и кэширование ключей
Как только доверие (trust) между vCenter и KMS установлено, можно активировать шифрование vSAN на уровне кластера. При этом vCenter от имени кластера делает запрос в KMS на выдачу необходимых ключей (KEK и Host Key) и распределяет их идентификаторы хостам, как описано выше. Каждый ESXi узел соединяется с KMS напрямую для получения своих ключей. На период нормальной работы vSAN-хосты обмениваются ключами с KMS напрямую, без участия vCenter.
Это означает, что после первоначальной настройки для ежедневной работы кластера шифрования доступность vCenter не критична – даже если vCenter временно выключен, хосты будут продолжать шифровать/расшифровывать данные, используя ранее полученные ключи. Однако vCenter нужен для проведения операций управления ключами (например, генерации новых ключей, смены KMS и пр.). Полученные ключи хранятся на хостах в памяти, а при наличии TPM-модуля – ещё и в его защищённом хранилище, что позволяет пережить перезагрузку хоста без немедленного запроса к KMS.
VMware настоятельно рекомендует оснащать все узлы vSAN доверенными платформенными модулями TPM 2.0, чтобы обеспечить устойчивость к отказу KMS: если KMS временно недоступен, хосты с TPM смогут перезапускаться и монтировать зашифрованное хранилище, используя кешированные в TPM ключи.
Лучшие практики KMS
В контексте vSAN есть важное правило: не размещать сам KMS на том же зашифрованном vSAN-хранилище, которое он обслуживает. Иначе возникает круговая зависимость: при отключении кластера или перезагрузке узлов KMS сам окажется недоступен (ведь он работал как ВМ на этом хранилище), и хосты не смогут получить ключи для расшифровки датасторов.
Лучше всего развернуть кластер KMS вне шифруемого кластера (например, на отдельной инфраструктуре или как облачный сервис) либо воспользоваться внешним NKP от другого vCenter. Также желательно настроить кластер из нескольких узлов KMS (для отказоустойчивости) либо, в случае NKP, надёжно сохранить резервную копию ключа (через функцию экспорта в UI vCenter).
При интеграции с KMS крайне важна корректная сетевая настройка: все хосты vSAN-кластера должны иметь прямой доступ к серверу KMS (обычно по протоколу TLS на порт 5696). В связке с KMS задействуйте DNS-имя для обращения (вместо IP) – это упростит перенастройку в случае смены адресов KMS и снизит риск проблем с подключением.
vSphere Native Key Provider
Этот встроенный механизм управления ключами в vCenter заслуживает отдельного упоминания. NKP позволяет обойтись без развертывания отдельного KMS-сервера, что особенно привлекательно для небольших компаний или филиалов. VMware поддерживает использование NKP для шифрования vSAN начиная с версии 7.0 U2. По сути, NKP хранит мастер-ключ в базе данных vCenter (в зашифрованном виде) и обеспечивает необходимые функции выдачи ключей гипервизорам. При включении шифрования vSAN с NKP процесс выдачи ключей аналогичен: vCenter генерирует KEK и распределяет его на хосты. Разница в том, что здесь нет внешнего сервера – все операции выполняются средствами самого vCenter.
Несмотря на удобство, у NKP есть ограничения (например, отсутствие поддержки внешних интерфейсов KMIP для сторонних приложений), поэтому для крупных сред на долгосрочной основе часто выбирают полноценный внешний KMS. Тем не менее, NKP – это простой способ быстро задействовать шифрование без дополнительных затрат, и он идеально подходит для многих случаев использования.
После того как кластер vSAN сконфигурирован для шифрования и получены необходимые ключи, каждая операция записи данных проходит через этап шифрования в гипервизоре. Рассмотрим упрощённо этот процесс на примере OSA (Original Storage Architecture):
Получение блока данных. Виртуальная машина записывает данные на диск vSAN, которые через виртуальный контроллер поступают на слой vSAN внутри ESXi. Там данные сначала обрабатываются сервисами оптимизации – например, вычисляются хеши для дедупликации и выполняется сжатие (если эти функции включены на кластере).
Шифрование блока. Когда очередь дошла до фактической записи блока на устройство, гипервизор обращается к ключу данных (DEK), связанному с целевым диском, и шифрует блок по алгоритму AES-256 (режим XTS) с помощью этого DEK. Как упоминалось, в OSA у каждого диска свой DEK, поэтому даже два диска одного узла шифруют данные разными ключами. Шифрование происходит на уровне VMkernel, используя AES-NI, и добавляет минимальную задержку.
Запись на устройство. Зашифрованный блок записывается в кеш или напрямую на SSD в составе дисковой группы. На носитель попадают только зашифрованные данные; никакой незашифрованной копии информации на диске не сохраняется. Метаданные vSAN также могут быть зашифрованы или содержать ссылки на ключ (например, KEK_ID), но без владения самим ключом извлечь полезную информацию из зашифрованного блока невозможно.
В архитектуре ESA процесс схож, с тем отличием, что шифрование происходит сразу после сжатия, ещё на высокоуровневом слое ввода-вывода. Это означает, что данные выходят из узла уже шифрованными кластерным ключом. При наличии Data-in-Transit Encryption vSAN накладывает дополнительное пакетное шифрование: каждый сетевой пакет между хостами шифруется с использованием симметрических ключей сеанса, которые регулярно обновляются. Таким образом, данные остаются зашифрованы как при хранении, так и при передаче по сети, что создаёт многослойную защиту (end-to-end encryption).
Чтение данных (дешифрование)
Обратный процесс столь же прозрачен. Когда виртуальная машина запрашивает данные из vSAN, гипервизор на каждом затронутом хосте находит нужные зашифрованные блоки на дисках и считывает их. Прежде чем передать данные наверх VM, гипервизор с помощью соответствующего DEK выполняет расшифровку каждого блока в памяти. Расшифрованная информация проходит через механизмы пост-обработки (восстановление сжатых данных, сборка из дедуплицированных сегментов) и отправляется виртуальной машине. Для ВМ этот процесс невидим – она получает привычный для себя блок данных, не зная, что на физическом носителе он хранится в зашифрованном виде. Если задействовано шифрование трафика, то данные могут передаваться между узлами в зашифрованном виде и расшифровываются только на том хосте, который читает их для виртуальной машины-потребителя.
Устойчивость к сбоям
При нормальной работе все операции шифрования/дешифрования происходят мгновенно для пользователя. Но стоит рассмотреть ситуацию с потенциальным сбоем KMS или перезагрузкой узла. Как отмечалось ранее, хосты кэшируют полученные ключи (KEK, Host Key и необходимые DEK) в памяти или TPM, поэтому кратковременное отключение KMS не влияет на работающий кластер.
Виртуальные машины продолжат и читать, и записывать данные, пользуясь уже загруженными ключами. Проблемы могут возникнуть, если перезагрузить хост при недоступном KMS: после перезапуска узел не сможет получить свои ключи для монтирования дисковых групп, и его локальные компоненты хранилища останутся офлайн до восстановления связи с KMS. Именно поэтому, как уже упоминалось, рекомендуется иметь резервный KMS (или NKP) и TPM-модули на узлах, чтобы повысить отказоустойчивость системы шифрования.
Безопасность криптосистемы во многом зависит от регулярной смены ключей. VMware vSAN предоставляет администраторам возможность проводить плановую ротацию ключей шифрования без простоя и с минимальным влиянием на работу кластера. Поддерживаются два режима: «мелкая» ротация (Shallow Rekey) и «глубокая» ротация (Deep Rekey). При shallow rekey генерируется новый мастер-ключ KEK, после чего все ключи данных (DEK) перешифровываются этим новым KEK (старый KEK уничтожается). Важно, что сами DEK при этом не меняются, поэтому операция выполняется относительно быстро: vSAN просто обновляет ключи в памяти хостов и в метаданных, не перестраивая все данные на дисках. Shallow rekey обычно используют для регулярной смены ключей в целях комплаенса (например, раз в квартал или при смене ответственного администратора).
Deep rekey, напротив, предполагает полную замену всех ключей: генерируются новые DEK для каждого объекта/диска, и все данные кластера постепенно перераспределяются и шифруются уже под новыми ключами. Такая операция более ресурсоёмка, фактически аналогична повторному шифрованию всего объёма данных, и может занять продолжительное время на крупных массивах. Глубокую ротацию имеет смысл выполнять редко – например, при подозрении на компрометацию старых ключей или после аварийного восстановления системы, когда есть риск утечки ключевой информации. Оба типа рекея можно инициировать через интерфейс vCenter (в настройках кластера vSAN есть опция «Generate new encryption keys») или с помощью PowerCLI-скриптов. При этом для shallow rekey виртуальные машины могут продолжать работать без простоев, а deep rekey обычно тоже выполняется онлайн, хотя и создаёт повышенную нагрузку на подсистему хранения.
Смена KMS и экспорт ключей
Если возникает необходимость поменять используемый KMS (например, миграция на другого вендора или переход от внешнего KMS к встроенному NKP), vSAN упрощает эту процедуру. Администратор добавляет новый KMS в vCenter и обозначает его активным для данного кластера. vSAN автоматически выполнит shallow rekey: запросит новый KEK у уже доверенного нового KMS и переведёт кластер на использование этого ключа, перешифровав им все старые DEK. Благодаря этому переключение ключевого сервиса происходит прозрачно, без остановки работы хранилища. Тем не менее, после замены KMS настоятельно рекомендуется удостовериться, что старый KMS более недоступен хостам (во избежание путаницы) и сделать резервную копию конфигурации нового KMS/NKP.
При использовании vSphere Native Key Provider важно регулярно экспортировать зашифрованную копию ключа NKP (через интерфейс vCenter) и хранить её в безопасном месте. Это позволит восстановить доступ к зашифрованному vSAN, если vCenter выйдет из строя и потребуется его переустановка. В случае же аппаратного KMS, как правило, достаточно держать под рукой актуальные резервные копии самого сервера KMS (или использовать кластер KMS из нескольких узлов для отказоустойчивости).
Безопасное удаление данных
Одним из побочных преимуществ внедрения шифрования является упрощение процедуры безопасной утилизации носителей. vSAN предлагает опцию Secure Disk Wipe для случаев, когда необходимо вывести диск из эксплуатации или изъять узел из кластера. При включенной функции шифрования проще всего выполнить «очистку» диска путем сброса ключей: как только DEK данного носителя уничтожен (либо кластерный KEK перегенерирован), все данные на диске навсегда остаются в зашифрованном виде, то есть фактически считаются стёртыми (так называемая криптографическая санация).
Кроме того, начиная с vSAN 8.0, доступна встроенная функция стирания данных в соответствии со стандартами NIST (например, перезапись нулями или генерация случайных шаблонов). Администратор может запустить безопасное стирание при выведении диска из кластера – vSAN приведёт накопитель в состояние, удовлетворяющее требованиям безопасной утилизации, удалив все остаточные данные. Комбинация шифрования и корректного удаления обеспечивает максимальную степень защиты: даже физически завладев снятым накопителем, злоумышленник не сможет извлечь конфиденциальные данные.
VMware vSAN Encryption Services были разработаны с учётом строгих требований отраслевых стандартов безопасности. Криптографический модуль VMkernel, на котором основано шифрование vSAN, прошёл валидацию FIPS 140-2 (Cryptographic Module Validation Program) ещё в 2017 году. Это означает, что реализация шифрования в гипервизоре проверена независимыми экспертами и отвечает критериям, предъявляемым правительственными организациями США и Канады.
Более того, в 2024 году VMware успешно завершила сертификацию модуля по новому стандарту FIPS 140-3, обеспечив преемственность соответствия более современным требованиям. Для заказчиков из сфер, где необходима сертификация (государственный сектор, финансы, медицина и т.д.), это даёт уверенность, что vSAN может использоваться для хранения чувствительных данных. Отдельно отметим, что vSAN включена в руководства по безопасности DISA STIG для Министерства обороны США, а также поддерживает механизмы двухфакторной аутентификации администраторов (RSA SecurID, CAC) при работе с vCenter — всё это подчёркивает серьёзное внимание VMware к безопасности решения.
Совместимость с функционалом vSAN
Шифрование в vSAN спроектировано так, чтобы быть максимально прозрачным для остальных возможностей хранения. Дедупликация и сжатие полностью совместимы с Data-at-Rest Encryption: благодаря порядку выполнения (сначала дедупликация/сжатие, потом шифрование) эффективность экономии места практически не снижается. Исключение составляет экспериментальная функция глобальной дедупликации в новой архитектуре ESA — на момент запуска vSAN 9.0 одновременное включение глобальной дедупликации и шифрования не поддерживается (ожидается снятие этого ограничения в будущих обновлениях).
Снапшоты и клоны виртуальных машин на зашифрованном vSAN работают штатно: все мгновенные копии хранятся в том же шифрованном виде, и при чтении/записи гипервизор так же прозрачно шифрует их содержимое. vMotion и другие механизмы миграции ВМ также поддерживаются – сама ВМ при миграции может передаваться с шифрованием (функция Encrypted vMotion, независимая от vSAN) или без него, но это не влияет на состояние ее дисков, которые на принимающей стороне всё равно будут записаны на vSAN уже в зашифрованном виде.
Резервное копирование и репликация
vSAN Encryption не накладывает ограничений на работу средств резервного копирования, использующих стандартные API vSphere (такие как VMware VADP) или репликации на уровне ВМ. Данные читаются гипервизором в расшифрованном виде выше уровня хранения, поэтому бэкап-приложения получают их так же, как и с обычного хранилища. При восстановлении или репликации на целевой кластер vSAN, естественно, данные будут записаны с повторным шифрованием под ключи того кластера. Таким образом, процессы защиты и восстановления данных (VDP, SRM, vSphere Replication и пр.) полностью совместимы с зашифрованными датасторами vSAN.
Ограничения и особенности
Поскольку vSAN реализует программное шифрование, аппаратные самошифрующиеся диски (SED) не требуются и официально не поддерживаются в роли средства шифрования на уровне vSAN. Если в серверы установлены SED-накопители, они могут использоваться, но без включения режимов аппаратного шифрования – vSAN в любом случае выполнит шифрование средствами гипервизора. Ещё один момент: при включении vSAN Encryption отключается возможность рентген-просмотра (в веб-клиенте vSAN) содержимого дисков, так как данные на них хранятся в зашифрованном виде. Однако на функциональность управления размещением объектов (Storage Policy) это не влияет. Наконец, стоит учитывать, что шифрование данных несколько повышает требования к процессорным ресурсам на хостах. Практика показывает, что современные CPU справляются с этим отлично, но при проектировании больших нагрузок (вроде VDI или баз данных на all-flash) закладывать небольшой запас по CPU будет не лишним.
VMware vSAN Encryption Services предоставляют мощные средства защиты данных для гиперконвергентной инфраструктуры. Реализовав сквозное шифрование (от диска до сети) на уровне хранения, vSAN позволяет организациям выполнить требования по безопасности без сложных доработок приложений. Среди ключевых преимуществ решения можно отметить:
Всесторонняя защита данных. Даже если злоумышленник получит физический доступ к носителям или перехватит трафик, конфиденциальная информация останется недоступной благодаря сильному шифрованию (AES-256) и раздельным ключам для разных объектов. Это особенно важно для соблюдения стандартов GDPR, PCI-DSS, HIPAA и других.
Прозрачность и совместимость. Шифрование vSAN работает под управлением гипервизора и не требует изменений в виртуальных машинах. Все основные функции vSphere (кластеризация, миграция, бэкап) полностью поддерживаются. Решение не привязано к специфическому оборудованию, а опирается на открытые стандарты (KMIP, TLS), что облегчает интеграцию.
Удобство централизованного управления. Администратор может включить шифрование для всего кластера несколькими кликами – без необходимости настраивать каждую ВМ по отдельности (в отличие от VMcrypt). vCenter предоставляет единый интерфейс для управления ключами, а встроенный NKP ещё больше упрощает старт. При этом разграничение прав доступа гарантирует, что только уполномоченные лица смогут внести изменения в политику шифрования.
Минимальное влияние на производительность. Благодаря оптимизациям (использование AES-NI, эффективные алгоритмы) накладные расходы на шифрование невелики. Особенно в архитектуре ESA шифрование реализовано с учётом высокопроизводительных сценариев и практически не сказывается на IOPS и задержках. Отсутствуют и накладные расходы по ёмкости: включение шифрования не уменьшает полезный объём хранилища и не создаёт дублирования данных.
Гибкость в выборе подхода. vSAN поддерживает как внешние KMS от разных поставщиков (для предприятий с уже выстроенными процессами управления ключами), так и встроенный vSphere Native Key Provider (для простоты и экономии). Администраторы могут ротировать ключи по своему графику, комбинировать или отключать сервисы при необходимости (например, включить только шифрование трафика для удалённого филиала с общим хранилищем).
При внедрении шифрования в vSAN следует учесть несколько моментов: обеспечить высокую доступность сервера KMS (или надёжно сохранить ключ NKP), активировать TPM на хостах для хранения ключей, а также не сочетать шифрование vSAN с шифрованием на уровне ВМ (VM Encryption) без крайней необходимости. Двойное шифрование не повышает безопасность, зато усложняет управление и снижает эффективность дедупликации и сжатия.
В целом же шифрование vSAN значительно повышает уровень безопасности инфраструктуры с минимальными усилиями. Оно даёт организациям уверенность, что данные всегда под надёжной защитой – будь то на дисках или в пути между узлами, сегодня и в будущем, благодаря следованию современным стандартам криптографии FIPS.
Решение с вызовом vSphere MOB и ручной генерацией XML-запроса для добавления хоста ESXi в нужный кластер vSphere в vCenter Server было, мягко говоря, неидеальным, но задачу оно выполняло. Сейчас это решение можно значительно улучшить, используя более современные подходы, при этом сохранив исходное требование: возможность добавить хост в кластер vSphere прямо из ESXi 8.x/9.x Kickstart без внешних зависимостей.
Шаг 1. Предполагаем, что у вас уже есть инфраструктура ESX Kickstart, готовая к работе.
Примечание: Для разработки Вильям настоятельно рекомендует использовать Nested ESXi и HTTP Boot через Virtual EFI — так вы сможете быстро протестировать автоматизацию ESX Kickstart перед тем, как развернуть её на реальном железе. Это позволит без особых усилий быстро создать рабочий прототип решения, которое вы увидите здесь.
Шаг 2. С помощью ChatGPT Вильяму удалось создать современную версию скрипта на основе Pyvmomi (vSphere SDK для Python), который использует тот же самый API vSphere для добавления хоста ESX в vCenter Server и его подключения к нужному кластеру vSphere. Скачайте скрипт add_host_to_cluster.py и разместите его на веб-сервере, с которого вы отдаёте конфигурацию ESX Kickstart, либо внедрите прямо в kickstart-файл.
Скрипт можно запускать локально на системе с установленным Pyvmomi или прямо на ESXi 8.x/9.x со следующим синтаксисом:
Шаг 3. Обновите ваш ESX Kickstart так, чтобы он запускал скрипт add_host_to_cluster.py с нужными параметрами. В данном примере и kickstart ESX, и скрипт add_host_to_cluster.py размещены на веб-сервере Вильяма, поэтому kickstart сначала загружает скрипт на хост ESX в рамках секции %firstboot, а затем запускает его с учётными данными для vCenter Server и хоста ESX, которые необходимы для вызова vSphere API.
Примечание: Скорее всего, вам НЕ следует использовать учётную запись администратора для добавления ESX-хоста. Вместо этого создайте сервисную учётную запись, у которой есть только права на добавление хостов в кластер vSphere и никакие другие роли, так как учётные данные придётся указывать в открытом виде (plain text).
Вот скриншот итогового решения, где Вильям смог быстро продемонстрировать это с помощью виртуальной машины Nested ESXi и загрузки по HTTP через Virtual EFI (см. ссылку в Шаге 1). ESX устанавливается автоматически, так же как и на физической машине, а затем, в рамках пост-настройки, загружается наш скрипт на Pyvmomi и хост присоединяется к нужному кластеру vSphere:
Во время конференции VMware Explore 2025 к блогеру Вильяму Ламу, много пишущему о технологиях виртуализации по существу, обратился один из участников, которого заинтересовала его физическая сетевая инфраструктура и то, как всё подключено в его лабораторной среде VMware Cloud Foundation (VCF) 9.0. Сетевая схема ниже основана на вот этой спецификации оборудования (Hardware BOM — Build-of-Material) для VCF 9.0:
В самой лаборатории используется следующая сетевая конфигурация с дополнительными комментариями к каждому подключению в описании ниже:
Примечание: все зелёные линии на схеме выше обозначают сетевые подключения 10 GbE, а все синие линии обозначают подключения 2.5 GbE.
Порты:
Роутер MikroTik (слева направо): порты 1–5
Роутер Sodola (слева направо): порты 1–6
Подключения портов:
Порт 1 на MikroTik подключен к интернет-аплинку
Это необходимо, если вам требуется исходящее подключение для установки/загрузки пакетов в вашу среду.
Порты 2–4 на MikroTik подключены к 3 x MS-A2 через первый порт 10GbE SFP+
ESXi определит первый SFP+ порт как vmnic1.
Порт 5 на MikroTik подключен к порту 6 (10GbE SFP+) на коммутаторе Sodola
Настроен как транковый VLAN (802.1Q), который будет передавать все VLAN’ы, определённые на MikroTik.
Порт 1 на Sodola подключен к настольному iMac
Настроен как нетегированный VLAN, и конкретно для сети Management, чтобы можно было получить доступ ко всем системам.
Порт 2 на Sodola подключен к ASUS NUC 14
Настроен как транковый VLAN (802.1Q) для дополнительного хоста с рабочими нагрузками VCF Workload Domain.
Порт 5 на Sodola подключен к Synology NAS
Настроен как тегированный VLAN для доступа к VCF Offline Depot.
Порты 3–4 на Sodola не используются и доступны для расширения системы.
Более подробно о тестовой лаборатории Вильяма можно почитать вот тут.
Недавно компания VMware опубликовала полезный для администраторов документ «vSphere 9.0 Performance Best Practices» с указанием ключевых рекомендаций по обеспечению максимальной производительности гипервизора ESX и инфраструктуры управления vCenter.
Документ охватывает ряд аспектов, начиная с аппаратных требований и заканчивая тонкой настройкой виртуальной инфраструктуры. Некоторые разделы включают не всем известные аспекты тонкой настройки:
Настройки BIOS: рекомендуется включить AES-NI, правильно сконфигурировать энергосбережение (например, «OS Controlled Mode»), при необходимости отключить некоторые C-states в особо чувствительных к задержкам приложениях.
vCenter и Content Library: советуют минимизировать автоматические скриптовые входы, использовать группировку vCenter для повышения синхронизации, хранить библиотеку контента на хранилищах с VAAI и ограничивать сетевую нагрузку через глобальный throttling.
Тонкое администрирование: правила доступа, лимиты, управление задачами, патчинг и обновления (включая рекомендации по BIOS и live scripts) и прочие глубокие настройки.
Отличия от версии для vSphere 8 (ESX и vCenter)
Аппаратные рекомендации
vSphere 8 предоставляет рекомендации по оборудованию: совместимость, минимальные требования, использование PMem (Optane, NVDIMM-N), vPMEM/vPMEMDisk, VAAI, NVMe, сетевые настройки, BIOS-опции и оптимизации I/O и памяти.
vSphere 9 добавляет новые аппаратные темы: фокус на AES-NI, snoop-режимах, NUMA-настройках, более гибком управлении энергопотреблением и безопасности на уровне BIOS.
vMotion и миграции
vSphere 8: введение «Unified Data Transport» (UDT) для ускорения холодных миграций и клонирования (при поддержке обеих сторон). Также рекомендации для связки encrypted vMotion и vSAN.
vSphere 9: больше внимания уделяется безопасности и производительности на стороне vCenter и BIOS, но UDT остаётся ключевым механизмом. В анонсах vSphere 9 в рамках Cloud Foundation акцент сделан на улучшенном управлении жизненным циклом и live patching.
Управление инфраструктурой
vSphere 8: рекомендации по vSphere Lifecycle Manager, UDT, обновлению vCenter и ESXi, GPU профили (в 8.0 Update 3) — включая поддержку разных vGPU, GPU Media Engine, dual DPU и live patch FSR.
vSphere 9 / VMware Cloud Foundation 9.0: новый подход к управлению жизненным циклом – поддержка live patch для vmkernel, NSX компонентов, более мощные «монстр-ВМ» (до 960 vCPU), direct upgrade с 8-й версии, image-based lifecycle management.
Работа с памятью
vSphere 8: рекомендации для Optane PMem, vPMEM/vPMEMDisk, управление памятью через ESXi.
vSphere 9 (через Cloud Foundation 9.0): внедрён memory tiering, позволяющий увеличить плотность ВМ в 2 раза при минимальной потере производительности (5%) и снижении TCO до 40%, без изменений в гостевой ОС.
Документ vSphere 9.0 Performance Best Practices содержит обновлённые и расширенные рекомендации для платформы vSphere 9, уделяющие внимание аппаратному уровню (BIOS-настройки, безопасность), инфраструктурному управлению, а также новым подходам к памяти (главный из них - memory tiering).
VMware представила унифицированный фреймворк разработки VCF SDK 9.0 для Python и Java.
Улучшение опыта разработчиков (Developer Experience) — один из главных приоритетов в дальнейшем развитии платформы VMware Cloud Foundation (VCF). Если рассматривать автоматизацию в целом, то можно выделить две чёткие категории пользователей: администраторы и разработчики.
Администраторы в основном сосредоточены на операционной автоматизации, включая развертывание, конфигурацию и управление жизненным циклом среды VCF. Их потребности в автоматизации обычно реализуются через написание скриптов и рабочих процессов, которые управляют инфраструктурой в масштабах всей организации.
Разработчики, напротив, ориентированы на интеграцию возможностей VCF в пользовательские приложения и решения. Им необходимы API и SDK, обеспечивающие программный доступ к сервисам и данным VCF, позволяя разрабатывать собственные инструменты, сервисы и расширения. Потребности в автоматизации у этих двух групп значительно различаются и соответствуют их уникальным ролям в экосистеме VCF. Понимая эти различия, Broadcom предлагает набор интерфейсов прикладного программирования (API), средств разработки (SDK) и разнообразных инструментов автоматизации, таких как PowerCLI, Terraform и Ansible.
Оглядываясь назад, можно сказать, что VMware хорошо обслуживала сообщество администраторов, предоставляя им различные инструменты. Однако API и SDK требовали улучшения в области документации, лучшей интеграции с VCF-стеком в целом и упрощения процесса для разработчиков. До выхода VCF 9.0 разработчики использовали отдельные SDK решений, сталкиваясь с трудностями, связанными с их интеграцией — такими как совместимость, аутентификация и сложность API. С выходом VCF 9.0 VMware рада объявить о доступности Unified VCF SDK 9.0. Давайте подробнее рассмотрим, что это такое.
Unified VCF SDK
Unified VCF SDK доступен с привязками к двум языкам — Java и Python. Это объединённый SDK, который включает в себя все основные SDK решений VCF в единый, упрощённый пакет. В своей первой версии Unified VCF SDK объединяет существующие SDK и добавляет новые библиотеки для установщика VCF и менеджера SDDC.
Список компонентов VCF, включённых в первую версию Unified VCF SDK:
VMware vSphere
VMware vSAN
VMware Cloud Foundation SDDC Manager (новый)
VMware Cloud Foundation Installer (новый)
VMware vSAN Data Protection
Несмотря на то, что Unified VCF SDK поставляется как единый пакет, пользователи могут устанавливать и использовать только те библиотеки, которые необходимы для конкретных задач.
Для краткости в этом тексте Unified VCF SDK будет обозначаться как VCF SDK.
Преимущества
VCF SDK обеспечивает простой, расширяемый и единообразный опыт для разработчиков на протяжении всего жизненного цикла разработки.
Упрощённый жизненный цикл разработчика
С этим релизом были стандартизированы методы доставки и распространения, чтобы поддерживать различные сценарии развертывания:
Онлайн-установка через PyPI (Python) и Maven (Java) — для прямого доступа и лёгкой установки/обновлений.
Офлайн-установка через портал разработчиков Broadcom — идеально для сред с ограниченным доступом в интернет.
Готовность к CI/CD — интеграции через пакеты и инструкции, размещённые на GitHub, для бесшовного включения в автоматизированные пайплайны при установке и обновлении.
Улучшенная документация и онбординг
VMware переработала документацию, чтобы упростить старт:
OpenAPI-спецификация описывает API в стандартизированном машинно-читаемом формате (YAML/JSON). С выходом VCF SDK были также публикованы OpenAPI-спецификации для API-эндпоинтов. Это не просто документация — это шаг к философии API-first и ориентированности на разработчиков.
С помощью OpenAPI-спецификаций разработчики могут:
Автоматически генерировать клиентские библиотеки на предпочитаемых языках с помощью инструментов вроде Swagger Codegen, Kiota или OpenAPI Generator.
Загружать спецификации в такие инструменты, как Swagger UI, Redoc или Postman, чтобы визуально исследовать доступные эндпоинты, параметры, схемы ответов и сообщения об ошибках.
pyVmomi — это Python SDK для API управления VMware vSphere, который позволяет быстро создавать решения, интегрированные с VMware ESX и vCenter Server.
vCenter Server
Библиотека VMware vCenter Server содержит клиентские привязки для автоматизационных API VMware vCenter Server.
VMware vSAN Data Protection
Библиотека VMware vSAN Data Protection содержит клиентские привязки для управления встроенными снапшотами, хранящимися локально в кластере vSAN, восстановления ВМ после сбоев или атак вымогателей и т.д.
Библиотека VMware SDDC Manager содержит клиентские привязки к автоматизационным API для управления компонентами инфраструктуры программно-определяемого датацентра (SDDC).
Установщик VMware Cloud Foundation (VCF Installer)
Модуль VCF Installer в составе VCF SDK содержит библиотеки для проверки, развертывания, преобразования и мониторинга установок VCF и VVF с использованием новых или уже существующих компонентов.
Каналы распространения
Unified VCF SDK доступен через различные каналы распространения. Это сделано для того, чтобы удовлетворить потребности разных типов сред и разработчиков — каждый может получить доступ к SDK в наиболее удобном для него месте. Ниже перечислены доступные каналы, откуда можно загрузить VCF SDK.
Портал разработчиков Broadcom
VCF Python SDK доступен для загрузки на портале разработчиков Broadcom. Вы можете распаковать содержимое ZIP-архива vcf-python-sdk-9.0.0.0-24798170.zip, чтобы ознакомиться с библиотеками SDK, утилитами и примерами. Однако сторонние зависимости не входят в состав архива — они перечислены в файле requirements-third-party.txt, находящемся внутри vcf-python-sdk-9.0.0.0-24798170.zip.
Файлы .whl компонентов VCF SDK находятся в папках ../pypi/*, а примеры кода для компонентов расположены в директориях вида /<имя_компонента>-samples/.
PyPI
VCF SDK доступен в PyPI, что позволяет разработчикам устанавливать и обновлять модуль онлайн. Это самый быстрый способ начать работу с VCF SDK.
Чтобы установить VCF SDK, выполните следующую команду:
$ pip install vcf-sdk
Пакеты, установленные через pip, можно автоматически обновлять. Чтобы обновить VCF SDK, используйте команду:
$ pip install --upgrade vcf-sdk
Чтобы установить конкретную библиотеку из состава VCF SDK, выполните:
Модуль vCenter в составе VCF SDK предоставляет операции, связанные с контент-библиотеками, развертыванием ресурсов, тегированием, а также управлением внутренними и внешними сертификатами безопасности.
Управление виртуальной инфраструктурой (VIM)
Модуль VIM (Virtual Infrastructure Management) предоставляет операции для управления вычислительными, сетевыми и хранилищными ресурсами. Эти ресурсы включают виртуальные машины, хосты ESXi, кластеры, хранилища данных, сети и системные абстракции, такие как события, тревоги, авторизация и расширения через плагины.
SSOCLIENT
Модуль единого входа (Single Sign-On) взаимодействует с сервисом Security Token Service (STS) для выдачи SAML-токенов, необходимых для аутентификации операций с API vCenter.
VMware vSAN Data Protection (vSAN DP)
С помощью встроенных снимков, локально хранящихся в кластере vSAN, модуль защиты данных vSAN обеспечивает быстрое восстановление ВМ после сбоев или атак вымогателей. API защиты данных vSAN управляет группами защиты и обнаруживает снимки виртуальных машин.
Управление жизненным циклом виртуального хранилища (VSLM)
Модуль VSLM (Virtual Storage Lifecycle Management) предоставляет операции, связанные с First Class Disks (FCD) — виртуальными дисками, не привязанными к конкретной виртуальной машине.
Служба мониторинга хранилища (SMS)
Модуль SMS (Storage Monitoring Service) предоставляет методы для получения информации о доступной топологии хранилищ, их возможностях и текущем состоянии. API Storage Awareness (VASA) позволяет хранилищам интегрироваться с vCenter для расширенного управления. Провайдеры VASA предоставляют данные о состоянии, конфигурации и емкости физических устройств хранения. SMS устанавливает и поддерживает соединения с провайдерами VASA и извлекает из них информацию о доступности хранилищ.
Управление на основе политик хранения (SPBM)
Модуль SPBM (Storage Policy Based Management) предоставляет операции для работы с политиками хранения. Эти политики описывают требования к хранению для виртуальных машин и возможности провайдеров хранения.
vSAN
Модуль vSAN предоставляет средства конфигурации и мониторинга vSAN-кластеров хранения и связанных сервисов на хостах ESXi и экземплярах vCenter Server. Включает функции работы с виртуальными дисками, такие как монтирование, разметка, безопасное удаление и создание снимков.
Менеджер агентов ESX (EAM)
Менеджер агентов ESX (ESX Agent Manager) позволяет разработчикам расширять функциональность среды vSphere путём регистрации пользовательских программ как расширений vCenter Server. EAM действует как посредник между vCenter и такими решениями, управляя развертыванием и мониторингом агентских ВМ и установочных пакетов VIB.
SDDC Manager
Модуль SDDC Manager предоставляет операции для управления и мониторинга физической и виртуальной инфраструктуры, развернутой в рамках VMware Cloud Foundation.
Установщик VMware Cloud Foundation (VCF Installer)
Модуль VCF Installer предоставляет операции для проверки, развертывания, преобразования и мониторинга установок VCF и VVF с использованием новых или уже существующих компонентов.
Каналы распространения
Аналогично Python SDK, JAVA SDK также доступен через различные каналы распространения, что позволяет использовать его в самых разных средах.
Портал разработчиков Broadcom
VCF Java SDK доступен для загрузки на портале разработчиков Broadcom. Вы можете распаковать содержимое ZIP-архива vcf-java-sdk-9.0.0.0-24798170.zip, чтобы ознакомиться с библиотеками SDK, утилитами и примерами.
Файлы привязок SDK .jar, утилит .jar, а также BOM-файлы находятся в папке:
../maven/com/vmware/*
Maven
Артефакты VCF SDK доступны в Maven Central под groupId: com.vmware.sdk. В таблице ниже указаны данные об артефактах VCF SDK для версии 9.0.0.0.
Чтобы начать работу с VCF SDK, добавьте зависимость в файл pom.xml вашего проекта:
С выходом VCF 9.0 VMware начала публиковать журнал изменений API. В нём отражаются все изменения: новые API, обновления существующих и уведомления об устаревании. Ознакомиться с журналом изменений можно здесь.
С выпуском VMware Cloud Foundation 9.0 объединение различных библиотек в один SDK с улучшенной документацией, примерами кода и спецификацией OpenAPI — это важный шаг к простому, расширяемому и согласованному опыту для разработчиков.
Следующий шаг за вами — попробуйте Unified VCF SDK 9.0 и поделитесь с нами своими отзывами.
«Альт Виртуализация» — это российское решение для построения и управления виртуальной инфраструктурой. Недавно вышедший релиз Альт Виртуализации версии 11.0 базируется на Proxmox VE 8.4 и предлагает унифицированный способ работы с виртуальными машинами (KVM/QEMU) и контейнерами (LXC) через веб-интерфейс, CLI и API. Поддерживаются архитектуры x86_64 и AArch64. Продукт включён в Реестр отечественного ПО Минцифры (рег.№ 6487) и выпускается в редакционном формате: сейчас доступна только PVE-версия, облачная готовится.
Основная функциональность продукта
1. Виртуализация серверов:
Полноценная аппаратная виртуализация под KVM/QEMU.
Лёгкие контейнеры LXC с поддержкой cgroups/namespaces.
2. Кластеризация и HA – обновлённая кластерная файловая система (pmxcfs), живая миграция, механизмы высокой доступности.
3. Сетевая инфраструктура – Linux bridge, Open vSwitch, VLAN, bonding, а теперь SDN с поддержкой VXLAN, QinQ и виртуальных сетей (VNets).
4. Хранилища – поддержка локальных (LVM, ZFS) и сетевых хранилищ (NFS, iSCSI, Ceph, GlusterFS и др.).
5. Резервное копирование – встроенные средства + интеграция с Proxmox Backup Server 3.3.
6. Безопасность и аутентификация – механизм ролевого доступа RBAC, поддержка PAM, LDAP, MS AD/Samba DC, OpenID Connect; OpenSSL 3.3 обеспечивает повышенную безопасность.
7. Поддержка GPU/PCI passthrough – возможность напрямую передавать устройства в ВМ.
8. Интеграция и API – единый Web GUI, CLI (с автодополнением), RESTful API на JSON для внешних интеграций.
Новшества в версии Альт Виртуализация 11.0
1. Улучшенный установщик
Быстрая установка с выбором файловых систем Ext4 или Btrfs (RAID 0/1/10), автоматическим созданием LVM-thin.
Интегрированный сетевой раздел с поддержкой VLAN, автоматическим мостом vmbr0, DNS и доменами.
2. SDN-подсистема
Полная поддержка SDN: создание виртуальных сетевых зон, сегментаций, изоляции, VNets и управление трафиком.
3. Графический апдейт
Из веб-интерфейса можно подключать и отключать репозитории, обновлять систему и пакеты без CLI.
4. Упрощённая архитектура
Контейнеризация на базе Kubernetes, Docker, CRI-O, Podman вынесена в «Альт Сервер 11.0», что позволило повысить стабильность и упрощённость PVE-системы.
Для виртуализации остался только LXC.
5. Импорт из VMware ESXi
Новый инструмент упрощает миграцию: импортирует VMDK + конфигурации сети и дисков напрямую из ESXi.
6. Обновление компонентов
Основные версии: PVE 8.4, LXC 6.0, QEMU 9.2, Ceph 19.2, Open vSwitch 3.3, Corosync 3.1, ZFS 2.3, OpenSSL 3.3.
Зачем всё это нужно
Быстрая и простая установка снижает порог входа и риски ошибок.
SDN-поддержка позволяет строить сложную и безопасную сетевую инфраструктуру без стороннего ПО.
Гибкое обновление через GUI упрощает эксплуатацию.
Упрощённая среда без лишних контейнерных инструментов — более надёжна и менее уязвима.
Прямая миграция с VMware облегчает переход на отечественные решения.
Современные компоненты поднимают производительность, безопасность и совместимость.
Заключение
«Альт Виртуализация 11.0» — важный шаг вперёд для российской виртуализации. Упрощённая установка, расширенные сетевые возможности, интеграция с системами резервного копирования и удобное обновление делают платформу достойным решением для корпоративного уровня. Первоначальный фокус на PVE-редакции с дальнейшим выходом облачной версии обеспечит гибкость и масштабируемость.
В условиях ухода западных вендоров с российского рынка и активного импортозамещения, спрос на отечественные платформы виртуализации значительно вырос. Одним из наиболее ярких и амбициозных проектов в этой области является «Иридиум», решение компании РТ-Иридиум, предназначенное для построения отказоустойчивой и масштабируемой виртуальной инфраструктуры. В июле 2025 года был представлен релиз «Иридиум» 2.0, вобравший в себя широкий набор корпоративных функций.
Архитектура и технологическая база
Платформа «Иридиум» построена на базе гипервизора KVM/QEMU — проверенного временем решения с открытым исходным кодом, которое активно используется и в других коммерческих продуктах (в том числе в ROSA Virtualization и Proxmox). Использование KVM обеспечивает высокую производительность, гибкость, поддержку современных функций виртуализации, а также совместимость с отечественным оборудованием.
Компоненты архитектуры «Иридиум»:
Гипервизор: KVM (работает на Linux, взаимодействует с аппаратной виртуализацией через Intel VT-x/AMD-V).
Управляющая панель: web-интерфейс с ролью диспетчера и оркестратора (аналог vCenter).
VSAN-подобное хранилище: поддержка отказоустойчивого кластера хранения.
Система управления пользователями и политиками безопасности (в том числе LDAP, SSO).
Интеграция с Docker-контейнерами — что делает платформу применимой не только для ВМ, но и для микросервисных архитектур.
Кластеры высокой доступности — объединение до 64 физических узлов с горячей миграцией и автоматическим восстановлением ВМ.
Новые возможности в версии 2.0
Релиз «Иридиум» 2.0 вывел продукт на уровень зрелого корпоративного решения. В числе ключевых новшеств:
HA-кластеры (High Availability) — автоматическое восстановление ВМ при сбое узла.
Горячая и холодная миграция виртуальных машин между узлами.
Встроенное резервное копирование и восстановление.
Поддержка VDI-сценариев (виртуальных рабочих столов).
Контроль доступа и кросс-доменная авторизация.
Новая панель мониторинга с метриками и журналами аудита.
Совместимость с российскими серверами (например, RDW Computers), включая проверку отказоустойчивости.
Сравнение с конкурентами
Характеристика
Иридиум 2.0
ROSA Virtualization
VMware vSphere
Основа гипервизора
KVM/QEMU
KVM/QEMU
Собственный гипервизор ESXi
Интерфейс управления
Web UI, REST API
Web UI (на базе Cockpit)
vCenter
Горячая миграция ВМ
Да
Да
Да
Кластеры высокой доступности
Да
Ограниченно (в Enterprise)
Да (через vSphere HA)
Поддержка VDI
Да
Нет (только через сторонние решения)
Да (через Omnissa)
Репликация и бэкапы
Встроенные
Через сторонние решения
Через Veeam, vSphere Replication
Сертификация ФСТЭК
В процессе получения
Есть (у отдельных сборок)
Нет (нерелевантно для РФ после ухода)
Docker/контейнеры
Да (встроено)
Частично (в экспериментальных сборках)
Через Tanzu (Kubernetes)
Импортозамещение/локализация
Отечественная сборка на базе Open Source
Отечественная сборка на базе Open Source
Нет (не поддерживается в РФ)
Заключение
С выходом версии 2.0 платформа «Иридиум» совершила качественный скачок, превратившись в конкурентоспособную альтернативу западным решениям уровня VMware. Поддержка кластеров высокой доступности, встроенное резервное копирование, интерфейс управления и интеграция с VDI делают продукт особенно привлекательным для корпоративных клиентов, органов власти и критически важных объектов инфраструктуры.
Благодаря открытому гипервизору KVM, российской разработке, масштабируемости и активной интеграции с отечественным «железом», «Иридиум» становится не просто ответом на уход VMware, но полноценным участником новой экосистемы российских ИТ-решений.
Новая версия платформы VMware Cloud Foundation 9.0, включающая компоненты виртуализации серверов и хранилищ VMware vSphere 9.0, а также виртуализации сетей VMware NSX 9, привносит не только множество улучшений, но и устраняет ряд устаревших технологий и функций. Многие возможности, присутствовавшие в предыдущих релизах ESX (ранее ESXi), vCenter и NSX, в VCF 9 объявлены устаревшими (deprecated) или полностью удалены (removed). Это сделано для упрощения архитектуры, повышения безопасности и перехода на новые подходы к архитектуре частных и публичных облаков. Ниже мы подробно рассмотрим, каких функций больше нет во vSphere 9 (в компонентах ESX и vCenter) и NSX 9, и какие альтернативы или рекомендации по миграции существуют для администраторов и архитекторов.
Почему важно знать об удалённых функциях?
Новые релизы часто сопровождаются уведомлениями об устаревании и окончании поддержки прежних возможностей. Игнорирование этих изменений может привести к проблемам при обновлении и эксплуатации. Поэтому до перехода на VCF 9 следует проанализировать, используете ли вы какие-либо из перечисленных ниже функций, и заранее спланировать отказ от них или переход на новые инструменты.
VMware vSphere 9: удалённые и устаревшие функции ESX и vCenter
В VMware vSphere 9.0 (гипервизор ESX 9.0 и сервер управления vCenter Server 9.0) прекращена поддержка ряда старых средств администрирования и внедрены новые подходы. Ниже перечислены основные функции, устаревшие (подлежащие удалению в будущих версиях) или удалённые уже в версии 9, а также рекомендации по переходу на современные альтернативы:
vSphere Auto Deploy (устарела) – сервис автоматического развертывания ESXi-хостов по сети (PXE-boot) объявлен устаревшим. В ESX 9.0 возможность Auto Deploy (в связке с Host Profiles) будет удалена в одном из следующих выпусков линейки 9.x.
Рекомендация: если вы использовали Auto Deploy для бездискового развёртывания хостов, начните планировать переход на установку ESXi на локальные диски либо использование скриптов для автоматизации установки. В дальнейшем управление конфигурацией хостов следует осуществлять через образы vLCM и vSphere Configuration Profiles, а не через загрузку по сети.
vSphere Host Profiles (устарела) – механизм профилей хоста, позволявший применять единые настройки ко многим ESXi, будет заменён новой системой конфигураций. Начиная с vCenter 9.0, функциональность Host Profiles объявлена устаревшей и будет полностью удалена в будущих версиях.
Рекомендация: вместо Host Profiles используйте vSphere Configuration Profiles, позволяющие управлять настройками на уровне кластера. Новый подход интегрирован с жизненным циклом vLCM и обеспечит более надежную и простую поддержку конфигураций.
vSphere ESX Image Builder (устарела) – инструмент для создания кастомных образов ESXi (добавления драйверов и VIB-пакетов) больше не развивается. Функциональность Image Builder фактически поглощена возможностями vSphere Lifecycle Manager (vLCM): в vSphere 9 вы можете создавать библиотеку образов ESX на уровне vCenter и собирать желаемый образ из компонентов (драйверов, надстроек от вендоров и т.д.) прямо в vCenter.
Рекомендация: для формирования образов ESXi используйте vLCM Desired State Images и новую функцию ESX Image Library в vCenter 9, которая позволит единообразно управлять образами для кластеров вместо ручной сборки ISO-файлов.
vSphere Virtual Volumes (vVols, устарела) – технология виртуальных томов хранения объявлена устаревшей с выпуском VCF 9.0 / vSphere 9.0. Поддержка vVols отныне будет осуществляться только для критических исправлений в vSphere 8.x (VCF 5.x) до конца их поддержки. В VCF/VVF 9.1 функциональность vVols планируется полностью удалить.
Рекомендация: если в вашей инфраструктуре используются хранилища на основе vVols, следует подготовиться к миграции виртуальных машин на альтернативные хранилища. Предпочтительно задействовать VMFS или vSAN, либо проверить у вашего поставщика СХД доступность поддержки vVols в VCF 9.0 (в индивидуальном порядке возможна ограниченная поддержка, по согласованию с Broadcom). В долгосрочной перспективе стратегия VMware явно смещается в сторону vSAN и NVMe, поэтому использование vVols нужно минимизировать.
vCenter Enhanced Linked Mode (устарела) – расширенный связанный режим vCenter (ELM), позволявший объединять несколько vCenter Server в единый домен SSO с общей консолью, более не используется во VCF 9. В vCenter 9.0 ELM объявлен устаревшим и будет удалён в будущих версиях. Хотя поддержка ELM сохраняется в версии 9 для возможности обновления существующих инфраструктур, сама архитектура VCF 9 переходит на иной подход: единое управление несколькими vCenter осуществляется средствами VCF Operations вместо связанного режима.
Рекомендация: при планировании VCF 9 откажитесь от развёртывания новых связанных групп vCenter. После обновления до версии 9 рассмотрите перевод существующих vCenter из ELM в раздельный режим с группированием через VCF Operations (который обеспечивает центральное управление без традиционного ELM). Функции, ранее обеспечивавшиеся ELM (единый SSO, объединённые роли, синхронизация тегов, общая точка API и пр.), теперь достигаются за счёт возможностей VCF Operations и связанных сервисов.
vSphere Clustering Service (vCLS, устарела) – встроенный сервис кластеризации, который с vSphere 7 U1 запускал небольшие служебные ВМ (vCLS VMs) для поддержки DRS и HA, в vSphere 9 более не нужен. В vCenter 9.0 сервис vCLS помечен устаревшим и подлежит удалению в будущем. Кластеры vSphere 9 могут работать без этих вспомогательных ВМ: после обновления появится возможность включить Retreat Mode и отключить развёртывание vCLS-агентов без какого-либо ущерба для функциональности DRS/HA.
Рекомендация: отключите vCLS на кластерах vSphere 9 (включив режим Retreat Mode в настройках кластера) – деактивация vCLS никак не влияет на работу DRS и HA. Внутри ESX 9 реализовано распределенное хранилище состояния кластера (embedded key-value store) непосредственно на хостах, благодаря чему кластер может сохранять и восстанавливать свою конфигурацию без внешних вспомогательных ВМ. В результате вы упростите окружение (больше никаких «мусорных» служебных ВМ) и избавитесь от связанных с ними накладных расходов.
ESX Host Cache (устарела) - в версии ESX 9.0 использование кэша на уровне хоста (SSD) в качестве кэша с обратной записью (write-back) для файлов подкачки виртуальных машин (swap) объявлено устаревшим и будет удалено в одной из будущих версий. В качестве альтернативы предлагается использовать механизм многоуровневой памяти (Memory Tiering) на базе NVMe. Memory Tiering с NVMe позволяет увеличить объём доступной оперативной памяти на хосте и интеллектуально распределять память виртуальной машины между быстрой динамической оперативной памятью (DRAM) и NVMe-накопителем на хосте.
Рекомендация: используйте функции Advanced Memory Tiering на базе NVMe-устройств в качестве второго уровня памяти. Это позволяет увеличить объём доступной памяти до 4 раз, задействуя при этом существующие слоты сервера для недорогого оборудования.
Память Intel Optane Persistent Memory (удалена) - в версии ESX 9.0 прекращена поддержка технологии Intel Optane Persistent Memory (PMEM). Для выбора альтернативных решений обратитесь к представителям вашего OEM-поставщика серверного оборудования.
Рекомендация:
в качестве альтернативы вы можете использовать функционал многоуровневой памяти (Memory Tiering), официально представленный в ESX 9.0. Эта технология позволяет добавлять локальные NVMe-устройства на хост ESX в качестве дополнительного уровня памяти. Дополнительные подробности смотрите в статье базы знаний VMware KB 326910.
Технология Storage I/O Control (SIOC) и балансировщик нагрузки Storage DRS (удалены) - в версии vCenter 9.0 прекращена поддержка балансировщика нагрузки Storage DRS (SDRS) на основе ввода-вывода (I/O Load Balancer), балансировщика SDRS на основе резервирования ввода-вывода (SDRS I/O Reservations-based load balancer), а также компонента vSphere Storage I/O Control (SIOC). Эти функции продолжают поддерживаться в текущих релизах 8.x и 7.x. Удаление указанных компонентов затрагивает балансировку нагрузки на основе задержек ввода-вывода (I/O latency-based load balancing) и балансировку на основе резервирования ввода-вывода (I/O reservations-based load balancing) между хранилищами данных (datastores), входящими в кластер хранилищ Storage DRS. Кроме того, прекращена поддержка активации функции Storage I/O Control (SIOC) на отдельном хранилище и настройки резервирования (Reservations) и долей (Shares) с помощью политик хранения SPBM Storage Policy. При этом первоначальное размещение виртуальных машин с помощью Storage DRS (initial placement), а также балансировка нагрузки на основе свободного пространства и политик SPBM Storage Policy (для лимитов) не затронуты и продолжают работать в vCenter 9.0.
Рекомендация: администраторам рекомендуется нужно перейти на балансировку нагрузки на основе свободного пространства и политик SPBM. Настройки резервирований и долей ввода-вывода (Reservations, Shares) через SPBM следует заменить альтернативными механизмами контроля производительности со стороны используемых систем хранения (например, встроенными функциями QoS). После миграции необходимо обеспечить мониторинг производительности, чтобы своевременно устранять возможные проблемы.
vSphere Lifecycle Manager Baselines (удалена) – классический режим управления патчами через базовые уровни (baselines) в vSphere 9 не поддерживается. Начиная с vCenter 9.0 полностью удалён функционал VUM/vLCM Baselines – все кластеры и хосты должны использовать только рабочий процесс управления жизненным циклом на базе образов (image-based lifecycle). При обновлении с vSphere 8 имеющиеся кластеры на baselines придётся перевести на работу с образами, прежде чем поднять их до ESX 9.
Рекомендация: перейдите от использования устаревших базовых уровней к vLCM images – желаемым образам кластера. vSphere 9 позволяет применять один образ к нескольким кластерам или хостам сразу, управлять соответствием (compliance) и обновлениями на глобальном уровне. Это упростит администрирование и устранит необходимость в ручном создании и применении множества baseline-профилей.
Integrated Windows Authentication (IWA, удалена) – в vCenter 9.0 прекращена поддержка интегрированной Windows-аутентификации (прямого добавления vCenter в домен AD). Вместо IWA следует использовать LDAP(S) или федерацию. VMware официально заявляет, что vCenter 9.0 более не поддерживает IWA, и для обеспечения безопасного доступа необходимо мигрировать учетные записи на Active Directory over LDAPS или настроить федерацию (например, через ADFS) с многофакторной аутентификацией.
Рекомендация: до обновления vCenter отключите IWA, переведите интеграцию с AD на LDAP(S), либо настройте VMware Identity Federation с MFA (эта возможность появилась начиная с vSphere 7). Это позволит сохранить доменную интеграцию vCenter в безопасном режиме после перехода на версию 9.
Локализации интерфейса (сокращены) – В vSphere 9 уменьшено число поддерживаемых языков веб-интерфейса. Если ранее vCenter поддерживал множество языковых пакетов, то в версии 9 оставлены лишь английский (US) и три локали: японский, испанский и французский. Все остальные языки (включая русский) более недоступны.
Рекомендация: администраторы, использующие интерфейс vSphere Client на других языках, должны быть готовы работать на английском либо на одной из трёх оставшихся локалей. Учебные материалы и документацию стоит ориентировать на английскую версию интерфейса, чтобы избежать недопонимания.
Общий совет по миграции для vSphere: заранее инвентаризуйте использование перечисленных функций в вашей инфраструктуре. Переход на vSphere 9 – удобный повод внедрить новые подходы: заменить Host Profiles на Configuration Profiles, перейти от VUM-бейзлайнов к образам, отказаться от ELM в пользу новых средств управления и т.д. Благодаря этому обновление пройдет более гладко, а ваша платформа будет соответствовать современным рекомендациям VMware.
Мы привели, конечно же, список только самых важных функций VMware vSphere 9, которые подверглись устареванию или удалению, для получения полной информации обратитесь к этой статье Broadcom.
VMware NSX 9: Устаревшие и неподдерживаемые функции
VMware NSX 9.0 (ранее известный как NSX-T) – компонент виртуализации сети в составе VCF 9 – также претерпел существенные изменения. Новая версия NSX ориентирована на унифицированную работу с VMware Cloud Foundation и отказывается от ряда старых возможностей, особенно связанных с гибкостью поддержки разных платформ. Вот ключевые технологии, не поддерживаемые больше в NSX 9, и как к этому адаптироваться:
Подключение физических серверов через NSX-Agent (удалено) – В NSX 9.0 больше не поддерживается развёртывание NSX bare-metal agent на физических серверах для включения их в оверлей NSX. Ранее такие агенты позволяли физическим узлам участвовать в логических сегментах NSX (оверлейных сетях). Начиная с версии 9, оверлейная взаимосвязь с физическими серверами не поддерживается – безопасность для физических серверов (DFW) остаётся, а вот L2-overlay connectivity убрана.
Рекомендация: для подключения физических нагрузок к виртуальным сетям NSX теперь следует использовать L2-мосты (bridge) на NSX Edge. VMware прямо рекомендует для новых подключений физических серверов задействовать NSX Edge bridging для обеспечения L2-связности с оверлеем, вместо установки агентов на сами серверы. То есть физические серверы подключаются в VLAN, который бриджится в логический сегмент NSX через Edge Node. Это позволяет интегрировать физическую инфраструктуру с виртуальной без установки NSX компонентов на сами серверы. Если у вас были реализованы bare-metal transport node в старых версиях NSX-T 3.x, их придётся переработать на схему с Edge-бриджами перед обновлением до NSX 9. Примечание: распределённый мост Distributed TGW, появившийся в VCF 9, также может обеспечить выход ВМ напрямую на ToR без Edge-узла, что актуально для продвинутых случаев, но базовый подход – через Edge L2 bridge.
Виртуальный коммутатор N-VDS на ESXi (удалён) – исторически NSX-T использовала собственный виртуальный коммутатор N-VDS для хостов ESXi и KVM. В NSX 9 эта технология более не применяется для ESX-хостов. Поддержка NSX N-VDS на хостах ESX удалена, начиная с NSX 4.0.0.1 (соответствует VCF 9). Теперь NSX интегрируется только с родным vSphere Distributed Switch (VDS) версии 7.0 и выше. Это означает, что все среды на ESX должны использовать конвергентный коммутатор VDS для работы NSX. N-VDS остаётся лишь в некоторых случаях: на Edge-нодах и для агентов в публичных облаках или на bare-metal Linux (где нет vSphere), но на гипервизорах ESX – больше нет.
Рекомендация: перед обновлением до NSX 9 мигрируйте все транспортные узлы ESXi с N-VDS на VDS. VMware предоставила инструменты миграции host switch (начиная с NSX 3.2) – ими следует воспользоваться, чтобы перевести существующие NSX-T 3.x host transport nodes на использование VDS. После перехода на NSX 9 вы получите более тесную интеграцию сети с vCenter и упростите управление, так как сетевые политики NSX привязываются к стандартному vSphere VDS. Учтите, что NSX 9 требует наличия vCenter для настройки сетей (фактически NSX теперь не работает автономно от vSphere), поэтому планируйте инфраструктуру исходя из этого.
Поддержка гипервизоров KVM и стороннего OpenStack (удалена) – NSX-T изначально позиционировался как мультигипервизорное решение, поддерживая кроме vSphere также KVM (Linux) и интеграцию с opensource OpenStack. Однако с выходом NSX 4.0 (и NSX 9) стратегия изменилась. NSX 9.0 больше не поддерживает гипервизоры KVM и дистрибутивы OpenStack от сторонних производителей. Поддерживается лишь VMware Integrated OpenStack (VIO) как исключение. Проще говоря, NSX сейчас нацелен исключительно на экосистему VMware.
Рекомендация: если у вас были развёрнуты политики NSX на KVM-хостах или вы использовали NSX-T совместно с не-VMware OpenStack, переход на NSX 9 невозможен без изменения архитектуры. Вам следует либо остаться на старых версиях NSX-T 3.x для таких сценариев, либо заменить сетевую виртуализацию в этих средах на альтернативные решения. В рамках же VCF 9 такая ситуация маловероятна, так как VCF подразумевает vSphere-стек. Таким образом, основное действие – убедиться, что все рабочие нагрузки NSX переведены на vSphere, либо изолировать NSX-T 3.x для специфичных нужд вне VCF. В будущем VMware будет развивать NSX как часть единой платформы, поэтому мультиплатформенные возможности урезаны в пользу оптимизации под vSphere.
NSX for vSphere (NSX-V) 6.x – не применяется – отдельно стоит упомянуть, что устаревшая платформа NSX-V (NSX 6.x для vSphere) полностью вышла из обращения и не входит в состав VCF 9. Её поддержка VMware прекращена еще в начале 2022 года, и миграция на NSX-T (NSX 4.x) стала обязательной. В VMware Cloud Foundation 4.x и выше NSX-V отсутствует, поэтому для обновления окружения старше VCF 3 потребуется заранее выполнить миграцию сетевой виртуализации на NSX-T.
Рекомендация: если вы ещё используете NSX-V в старых сегментах, необходимо развернуть параллельно NSX 4.x (NSX-T) и перенести сетевые политики и сервисы (можно с помощью утилиты Migration Coordinator, если поддерживается ваша версия). Только после перехода на NSX-T вы сможете обновиться до VCF 9. В новой архитектуре все сетевые функции будут обеспечиваться NSX 9, а NSX-V останется в прошлом.
Подводя итог по NSX: VMware NSX 9 сфокусирован на консолидации функций для частных облаков на базе vSphere. Возможности, выходящие за эти рамки (поддержка разнородных гипервизоров, агенты на физической базе и др.), были убраны ради упрощения и повышения производительности. Администраторам следует заранее учесть эти изменения: перевести сети на VDS, пересмотреть способы подключения физических серверов и убедиться, что все рабочие нагрузки, требующие NSX, работают в поддерживаемой конфигурации. Благодаря этому переход на VCF 9 будет предсказуемым, а новая среда – более унифицированной, безопасной и эффективной. Подготовившись к миграции от устаревших технологий на современные аналоги, вы сможете реализовать преимущества VMware Cloud Foundation 9.0 без длительных простоев и с минимальным риском для работы дата-центра.
Итоги
Большинство приведённых выше изменений официально перечислены в документации Product Support Notes к VMware Cloud Foundation 9.0 для vSphere и NSX. Перед обновлением настоятельно рекомендуется внимательно изучить примечания к выпуску и убедиться, что ни одна из устаревших функций, на которых зависит ваша инфраструктура, не окажется критичной после перехода. Следуя рекомендациям по переходу на новые инструменты (vLCM, Configuration Profiles, Edge Bridge и т.д.), вы обеспечите своей инфраструктуре поддерживаемость и готовность к будущим обновлениям в экосистеме VMware Cloud Foundation.
Итак, наконец-то начинаем рассказывать о новых возможностях платформы виртуализации VMware vSphere 9, которая является основой пакета решений VMware Cloud Foundation 9, о релизе которого компания Broadcom объявила несколько дней назад. Самое интересное - гипервизор теперь опять называется ESX, а не ESXi, который также стал последователем ESX в свое время :)
Управление жизненным циклом
Путь обновления vSphere
vSphere 9.0 поддерживает прямое обновление только с версии vSphere 8.0. Прямое обновление с vSphere 7.0 не поддерживается. vCenter 9.0 не поддерживает управление ESX 7.0 и более ранними версиями. Минимально поддерживаемая версия ESX, которую может обслуживать vCenter 9.0, — это ESX 8.0. Кластеры и отдельные хосты, управляемые на основе baseline-конфигураций (VMware Update Manager, VUM), не поддерживаются в vSphere 9. Кластеры и хосты должны использовать управление жизненным циклом только на основе образов.
Live Patch для большего числа компонентов ESX
Функция Live Patch теперь охватывает больше компонентов образа ESX, включая vmkernel и компоненты NSX. Это увеличивает частоту применения обновлений без перезагрузки. Компоненты NSX, теперь входящие в базовый образ ESX, можно обновлять через Live Patch без перевода хостов в режим обслуживания и без необходимости эвакуировать виртуальные машины.
Компоненты vmkernel, пользовательское пространство, vmx (исполнение виртуальных машин) и NSX теперь могут использовать Live Patch. Службы ESX (например, hostd) могут потребовать перезапуска во время применения Live Patch, что может привести к кратковременному отключению хостов ESX от vCenter. Это ожидаемое поведение и не влияет на работу запущенных виртуальных машин. vSphere Lifecycle Manager сообщает, какие службы или демоны будут перезапущены в рамках устранения уязвимостей через Live Patch. Если Live Patch применяется к среде vmx (исполнение виртуальных машин), запущенные ВМ выполнят быструю приостановку и восстановление (Fast-Suspend-Resume, FSR).
Live Patch совместим с кластерами vSAN. Однако узлы-свидетели vSAN (witness nodes) не поддерживают Live Patch и будут полностью перезагружаться при обновлении. Хосты, использующие TPM и/или DPU-устройства, в настоящее время не совместимы с Live Patch.
Создавайте кластеры по-своему с разным оборудованием
vSphere Lifecycle Manager поддерживает кластеры с оборудованием от разных производителей, а также работу с несколькими менеджерами поддержки оборудования (hardware support managers) в рамках одного кластера. vSAN также поддерживает кластеры с различным оборудованием.
Базовая версия ESX является неизменной для всех дополнительных образов и не может быть настроена. Однако надстройки от производителей (vendor addon), прошивка и компоненты в определении каждого образа могут быть настроены индивидуально для поддержки кластеров с разнородным оборудованием. Каждое дополнительное определение образа может быть связано с уникальным менеджером поддержки оборудования (HSM).
Дополнительные образы можно назначать вручную для подмножества хостов в кластере или автоматически — на основе информации из BIOS, включая значения Vendor, Model, OEM String и Family. Например, можно создать кластер, состоящий из 5 хостов Dell и 5 хостов HPE: хостам Dell можно назначить одно определение образа с надстройкой от Dell и менеджером Dell HSM, а хостам HPE — другое определение образа с надстройкой от HPE и HSM от HPE.
Масштабное управление несколькими образами
Образами vSphere Lifecycle Manager и их привязками к кластерам или хостам можно управлять на глобальном уровне — через vCenter, датацентр или папку. Одно определение образа может применяться к нескольким кластерам и/или отдельным хостам из единого централизованного интерфейса. Проверка на соответствие (Compliance), предварительная проверка (Pre-check), подготовка (Stage) и устранение (Remediation) также могут выполняться на этом же глобальном уровне.
Существующие кластеры и хосты с управлением на основе базовых конфигураций (VUM)
Существующие кластеры и отдельные хосты, работающие на ESX 8.x и использующие управление на основе базовых конфигураций (VUM), могут по-прежнему управляться через vSphere Lifecycle Manager, но для обновления до ESX 9 их необходимо перевести на управление на основе образов. Новые кластеры и хосты не могут использовать управление на основе baseline-конфигураций, даже если они работают на ESX 8. Новые кластеры и хосты автоматически используют управление жизненным циклом на основе образов.
Больше контроля над операциями жизненного цикла кластера
При устранении проблем (remediation) в кластерах теперь доступна новая возможность — применять исправления к подмножеству хостов в виде пакета. Это дополняет уже существующие варианты — обновление всего кластера целиком или одного хоста за раз.
Гибкость при выборе хостов для обновления
Описанные возможности дают клиентам гибкость — можно выбрать, какие хосты обновлять раньше других. Другой пример использования — если в кластере много узлов и обновить все за одно окно обслуживания невозможно, клиенты могут выбирать группы хостов и обновлять их поэтапно в несколько окон обслуживания.
Больше никакой неопределённости при обновлениях и патчах
Механизм рекомендаций vSphere Lifecycle Manager учитывает версию vCenter. Версия vCenter должна быть равной или выше целевой версии ESX. Например, если vCenter работает на версии 9.1, механизм рекомендаций не предложит обновление хостов ESX до 9.2, так как это приведёт к ситуации, где хосты будут иметь более новую версию, чем vCenter — что не поддерживается. vSphere Lifecycle Manager использует матрицу совместимости продуктов Broadcom VMware (Product Interoperability Matrix), чтобы убедиться, что целевой образ ESX совместим с текущей средой и поддерживается.
Упрощённые определения образов кластера
Компоненты vSphere HA и NSX теперь встроены в базовый образ ESX. Это делает управление их жизненным циклом и обеспечением совместимости более прозрачным и надёжным. Компоненты vSphere HA и NSX автоматически обновляются вместе с установкой патчей или обновлений базового образа ESX. Это ускоряет активацию NSX на кластерах vSphere, поскольку VIB-пакеты больше не требуется отдельно загружать и устанавливать через ESX Agent Manager (EAM).
Определение и применение конфигурации NSX для кластеров vSphere с помощью vSphere Configuration Profiles
Теперь появилась интеграция NSX с кластерами, управляемыми через vSphere Configuration Profiles. Профили транспортных узлов NSX (TNP — Transport Node Profiles) применяются с использованием vSphere Configuration Profiles. vSphere Configuration Profiles позволяют применять TNP к кластеру одновременно с другими изменениями конфигурации.
Применение TNP через NSX Manager отключено для кластеров с vSphere Configuration Profiles
Для кластеров, использующих vSphere Configuration Profiles, возможность применять TNP (Transport Node Profile) через NSX Manager отключена. Чтобы применить TNP с помощью vSphere Configuration Profiles, необходимо также задать:
набор правил брандмауэра с параметром DVFilter=true
настройку Syslog с параметром remote_host_max_msg_len=4096
Снижение рисков и простоев при обновлении vCenter
Функция Reduced Downtime Update (RDU) поддерживается при использовании установщика на базе CLI. Также доступны RDU API для автоматизации. RDU поддерживает как вручную настроенные топологии vCenter HA, так и любые другие топологии vCenter. RDU является рекомендуемым способом обновления, апгрейда или установки патчей для vCenter 9.0.
Обновление vCenter с использованием RDU можно выполнять через vSphere Client, CLI или API. Интерфейс управления виртуальным устройством (VAMI) и соответствующие API для патчинга также могут использоваться для обновлений без переустановки или миграции, однако при этом потребуется значительное время простоя.
Сетевые настройки целевой виртуальной машины vCenter поддерживают автоматическую конфигурацию, упрощающую передачу данных с исходного vCenter. Эта сеть автоматически настраивается на целевой и исходной виртуальных машинах vCenter с использованием адреса из диапазона Link-Local RFC3927 169.254.0.0/16. Это означает, что не требуется указывать статический IP-адрес или использовать DHCP для временной сети.
Этап переключения (switchover) может выполняться вручную, автоматически или теперь может быть запланирован на конкретную дату и время в будущем.
Управление ресурсами
Масштабирование объема памяти с более низкой стоимостью владения благодаря Memory Tiering с использованием NVMe
Memory Tiering использует устройства NVMe на шине PCIe как второй уровень оперативной памяти, что увеличивает доступный объем памяти на хосте ESX. Memory Tiering на базе NVMe снижает общую стоимость владения (TCO) и повышает плотность размещения виртуальных машин, направляя память ВМ либо на устройства NVMe, либо на более быструю оперативную память DRAM.
Это позволяет увеличить объем доступной памяти и количество рабочих нагрузок, одновременно снижая TCO. Также повышается эффективность использования процессорных ядер и консолидация серверов, что увеличивает плотность размещения рабочих нагрузок.
Функция Memory Tiering теперь доступна в производственной среде. В vSphere 8.0 Update 3 функция Memory Tiering была представлена в режиме технологического превью. Теперь же она стала доступна в режиме GA (General Availability) с выпуском VCF 9.0. Это позволяет использовать локально установленные устройства NVMe на хостах ESX как часть многоуровневой (tiered) памяти.
Повышенное время безотказной работы для AI/ML-нагрузок
Механизм Fast-Suspend-Resume (FSR) теперь работает значительно быстрее для виртуальных машин с поддержкой vGPU. Ранее при использовании двух видеокарт NVIDIA L40 с 48 ГБ памяти каждая, операция FSR занимала около 42 секунд. Теперь — всего около 2 секунд. FSR позволяет использовать Live Patch в кластерах, обрабатывающих задачи генеративного AI (Gen AI), без прерывания работы виртуальных машин.
Передача данных vGPU с высокой пропускной способностью
Канал передачи данных vGPU разработан для перемещения больших объемов данных и построен с использованием нескольких параллельных TCP-соединений и автоматического масштабирования до максимально доступной пропускной способности канала, обеспечивая прирост скорости до 3 раз (с 10 Гбит/с до 30 Гбит/с).
Благодаря использованию концепции "zero copy" количество операций копирования данных сокращается вдвое, устраняя узкое место, связанное с копированием, и дополнительно увеличивая пропускную способность при передаче.
vMotion с предкопированием (pre-copy) — это технология передачи памяти виртуальной машины на другой хост с минимальным временем простоя. Память виртуальной машины (как "холодная", так и "горячая") копируется в несколько проходов пока ВМ ещё работает, что устраняет необходимость полного чекпойнта и передачи всей памяти во время паузы, во время которой случается простой сервисов.
Улучшения в предкопировании холодных данных могут зависеть от характера нагрузки. Например, для задачи генеративного AI с большим объёмом статических данных ожидаемое время приостановки (stun-time) будет примерно:
~1 секунда для GPU-нагрузки объёмом 24 ГБ
~2 секунды для 48 ГБ
~22 секунды для крупной 640 ГБ GPU-нагрузки
Отображение профилей vGPU в vSphere DRS
Технология vGPU позволяет распределять физический GPU между несколькими виртуальными машинами, способствуя максимальному использованию ресурсов видеокарты.
В организациях с большим числом GPU со временем создаётся множество vGPU-профилей. Однако администраторы не могут легко просматривать уже созданные vGPU, что вынуждает их вручную отслеживать профили и их распределение по GPU. Такой ручной процесс отнимает время и снижает эффективность работы администраторов.
Отслеживание использования vGPU-профилей позволяет администраторам просматривать все vGPU во всей инфраструктуре GPU через удобный интерфейс в vCenter, устраняя необходимость ручного учёта vGPU. Это существенно сокращает время, затрачиваемое администраторами на управление ресурсами.
Интеллектуальное размещение GPU-ресурсов в vSphere DRS
В предыдущих версиях распределение виртуальных машин с vGPU могло приводить к ситуации, при которой ни один из хостов не мог удовлетворить требования нового профиля vGPU. Теперь же администраторы могут резервировать ресурсы GPU для будущего использования. Это позволяет заранее выделить GPU-ресурсы, например, для задач генеративного AI, что помогает избежать проблем с производительностью при развертывании таких приложений. С появлением этой новой функции администраторы смогут резервировать пулы ресурсов под конкретные vGPU-профили заранее, улучшая планирование ресурсов и повышая производительность и операционную эффективность.
Миграция шаблонов и медиафайлов с помощью Content Library Migration
Администраторы теперь могут перемещать существующие библиотеки контента на новые хранилища данных (datastore) - OVF/OVA-шаблоны, образы и другие элементы могут быть перенесены. Элементы, хранящиеся в формате VM Template (VMTX), не переносятся в целевой каталог библиотеки контента. Шаблоны виртуальных машин (VM Templates) всегда остаются в своем назначенном хранилище, а в библиотеке контента хранятся только ссылки на них.
Во время миграции библиотека контента перейдёт в режим обслуживания, а после завершения — снова станет активной. На время миграции весь контент библиотеки (за исключением шаблонов ВМ) будет недоступен. Изменения в библиотеке будут заблокированы, синхронизация с подписными библиотеками приостановлена.
vSphere vMotion между управляющими плоскостями (Management Planes)
Служба виртуальных машин (VM Service) теперь может импортировать виртуальные машины, находящиеся за пределами Supervisor-кластера, и взять их под своё управление.
Network I/O Control (NIOC) для vMotion с использованием Unified Data Transport (UDT)
В vSphere 8 был представлен протокол Unified Data Transport (UDT) для "холодной" миграции дисков, ранее выполнявшейся с использованием NFC. UDT значительно ускоряет холодную миграцию, но вместе с повышенной эффективностью увеличивается и нагрузка на сеть предоставления ресурсов (provisioning network), которая в текущей архитектуре использует общий канал с критически важным трафиком управления.
Чтобы предотвратить деградацию трафика управления, необходимо использовать Network I/O Control (NIOC) — он позволяет гарантировать приоритет управления даже при высокой сетевой нагрузке.
vSphere Distributed Switch 9 добавляет отдельную категорию системного трафика для provisioning, что позволяет применять настройки NIOC и обеспечить баланс между производительностью и стабильностью.
Provisioning/NFC-трафик: ресурсоёмкий, но низкоприоритетный
Provisioning/NFC-трафик (включая Network File Copy) является тяжеловесным и низкоприоритетным, но при этом использует ту же категорию трафика, что и управляющий (management), который должен быть легковесным и высокоприоритетным. С учетом того, что трафик provisioning/NFC стал ещё более агрессивным с внедрением NFC SOV (Streaming Over vMotion), вопрос времени, когда критически важный трафик управления начнёт страдать.
Существует договоренность с VCF: как только NIOC для provisioning/NFC будет реализован, можно будет включать NFC SOV в развёртываниях VCF. Это ускорит внедрение NFC SOV в продуктивных средах.
Расширение поддержки Hot-Add устройств с Enhanced VM DirectPath I/O
Устройства, которые не могут быть приостановлены (non-stunnable devices), теперь поддерживают Storage vMotion (но не обычный vMotion), а также горячее добавление виртуальных устройств, таких как:
vCPU
Память (Memory)
Сетевые адаптеры (NIC)
Примеры non-stunnable устройств:
Intel DLB (Dynamic Load Balancer)
AMD MI200 GPU
Гостевые ОС и рабочие нагрузки
Виртуальное оборудование версии 22 (Virtual Hardware Version 22)
Увеличен лимит vCPU до 960 на одну виртуальную машину
Поддержка новейших моделей процессоров от AMD и Intel
vTPM теперь поддерживает спецификацию TPM 2.0, версия 1.59.
ESX 9.0 соответствует TPM 2.0 Rev 1.59.
Это повышает уровень кибербезопасности, когда вы добавляете vTPM-устройство в виртуальную машину с версией 22 виртуального железа.
Новые vAPI для настройки гостевых систем (Guest Customization)
Представлен новый интерфейс CustomizationLive API, который позволяет применять спецификацию настройки (customization spec) к виртуальной машине в работающем состоянии (без выключения). Подробности — в последней документации по vSphere Automation API для VCF 9.0. Также добавлен новый API для настройки гостевых систем, который позволяет определить, можно ли применить настройку к конкретной ВМ, ещё до её применения.
В vSphere 9 появилась защита пространств имен (namespace) и поддержка Write Zeros для виртуальных NVMe. vSphere 9 вводит поддержку:
Namespace Write Protection - позволяет горячее добавление независимых непостоянных (non-persistent) дисков в виртуальную машину без создания дополнительных delta-дисков. Эта функция особенно полезна для рабочих нагрузок, которым требуется быстрое развёртывание приложений.
Write Zeros - для виртуальных NVMe-дисков улучшает производительность, эффективность хранения данных и дает возможности управления данными для различных типов нагрузок.
Безопасность, соответствие требованиям и отказоустойчивость виртуальных машин
Одним из частых запросов в последние годы была возможность использовать собственные сертификаты Secure Boot для ВМ. Обычно виртуальные машины работают "из коробки" с коммерческими ОС, но некоторые организации используют собственные ядра Linux и внутреннюю PKI-инфраструктуру для их подписи.
Теперь появилась прямая и удобная поддержка такой конфигурации — vSphere предоставляет механизм для загрузки виртуальных машин с кастомными сертификатами Secure Boot.
Обновлён список отозванных сертификатов Secure Boot
VMware обновила стандартный список отозванных сертификатов Secure Boot, поэтому при установке Windows на виртуальную машину с новой версией виртуального оборудования может потребоваться современный установочный образ Windows от Microsoft. Это не критично, но стоит иметь в виду, если установка вдруг не загружается.
Улучшения виртуального USB
Виртуальный USB — отличная функция, но VMware внесла ряд улучшений на основе отчётов исследователей по безопасности. Это ещё один веский аргумент в пользу того, чтобы поддерживать актуальность VMware Tools и версий виртуального оборудования.
Форензик-снапшоты (Forensic Snapshots)
Обычно мы стремимся к тому, чтобы снапшот ВМ можно было запустить повторно и обеспечить согласованность при сбое (crash-consistency), то есть чтобы система выглядела как будто питание отключилось. Большинство ОС, СУБД и приложений умеют с этим справляться.
Но в случае цифровой криминалистики и реагирования на инциденты, необходимость перезапускать ВМ заново отпадает — важнее получить снимок, пригодный для анализа в специальных инструментах.
Custom EVC — лучшая совместимость между разными поколениями CPU
Теперь вы можете создавать собственный профиль EVC (Enhanced vMotion Compatibility), определяя набор CPU- и графических инструкций, общих для всех выбранных хостов. Это решение более гибкое и динамичное, чем стандартные предустановленные профили EVC.
Custom EVC позволяет:
Указать хосты и/или кластеры, для которых vCenter сам рассчитает максимально возможный общий набор инструкций
Применять полученный профиль к кластерам или отдельным ВМ
Для работы требуется vCenter 9.0 и поддержка кластеров, содержащих хосты ESX 9.0 или 8.0. Теперь доступно более эффективное использование возможностей CPU при различиях между моделями - можно полнее использовать функции процессоров, даже если модели немного отличаются. Пример: два процессора одного поколения, но разных вариантов:
CPU-1 содержит функции A, B, D, E, F
CPU-2 содержит функции B, C, D, E, F
То есть: CPU-1 поддерживает FEATURE-A, но не FEATURE-C, CPU-2 — наоборот.
Custom EVC позволяет автоматически выбрать максимальный общий набор функций, доступный на всех хостах, исключая несовместимости:
В vSphere 9 появилась новая политика вычислений: «Limit VM placement span plus one host for maintenance» («ограничить размещение ВМ числом хостов плюс один для обслуживания»).
Эта политика упрощает соблюдение лицензионных требований и контроль использования лицензий. Администраторы теперь могут создавать политики на основе тегов, которые жестко ограничивают количество хостов, на которых может запускаться группа ВМ с лицензируемым приложением.
Больше не нужно вручную закреплять ВМ за хостами или создавать отдельные кластеры/хосты. Теперь администратору нужно просто:
Знать, сколько лицензий куплено.
Знать, на скольких хостах они могут применяться.
Создать политику с указанием числа хостов, без выбора конкретных.
Применить эту политику к ВМ с нужным тегом.
vSphere сама гарантирует, что такие ВМ смогут запускаться только на разрешённом числе хостов. Всегда учитывается N+1 хост в запас для обслуживания. Ограничение динамическое — не привязано к конкретным хостам.
Полный список новых возможностей VMware vSphere 9 также приведен в Release Notes.
Недавно мы рассказали об улучшениях и нововведениях платформы VMware Cloud Foundation 9.0, включающей в себя платформу виртуализации VMware vSphere 9.0 и средство создания отказоустойчивой инфраструктуры хранения VMware vSAN 9.0. Посмотрим теперь, что нового эти продукты включают с точки зрения сервисов хранилищ (Core Storage).
Улучшения поддержки хранилищ VCF
Для новых (greenfield) развёртываний VCF теперь поддерживаются хранилища VMFS, Fibre Channel и NFSv3 в качестве основных вариантов хранилища для домена управления. Полную информацию о поддержке хранилищ см. в технической документации VCF 9.
Улучшения NFS
Поддержка TRIM для NFS v3
Существующая поддержка команд TRIM и UNMAP позволяет блочным хранилищам, таким как vSAN и хранилища на базе VMFS, освобождать место после удаления файлов в виртуальной машине или при многократной записи в один и тот же файл. В типичных средах это позволяет освободить до 30% пространства, обеспечивая более эффективное использование ёмкости. С использованием плагина VAAI NFS системы NAS, подключённые через NFSv3, теперь могут выполнять освобождение пространства в VCF 9.
Шифрование данных в процессе передачи для NFS 4.1
Krb5p шифрует трафик NFS при передаче. Шифрование данных «на лету» защищает данные при передаче между хостами и NAS, предотвращая несанкционированный доступ и обеспечивая конфиденциальность информации организации, особенно в случае атак типа «man-in-the-middle». Также будет доступен режим Krb5i, который не выполняет шифрование, но обеспечивает проверку целостности данных, исключая их подмену.
Улучшения базовой подсистемы хранения
Сквозная (End-to-End, E2E) поддержка 4Kn
В версии 9.0 реализована поддержка E2E 4Kn, включающая:
Фронтэнд — представление виртуальных дисков (VMDK) с сектором 4K для виртуальных машин.
Бэкэнд — использование SSD-накопителей NVMe с 4Kn для vSAN ESA. OSA не поддерживает 4Kn SSD.
ESXi также получает поддержку 4Kn SSD с интерфейсом SCSI для локального VMFS и внешних хранилищ.
SEsparse по умолчанию для снимков с NFS и VMFS-5
Исторически, создание снимков (snapshots) имело значительное влияние на производительность ввода-вывода.
Формат Space Efficient Sparse Virtual Disks (SEsparse) был разработан для устранения двух основных проблем формата vmfsSparse:
Освобождение пространства при использовании снимков — SEsparse позволяет выполнять более точную и настраиваемую очистку места, что особенно актуально для VDI-сценариев.
Задержки чтения и снижение производительности из-за множественных операций чтения при работе со снимками.
Производительность была повышена благодаря использованию вероятностной структуры данных, такой как Bloom Filter, особенно для снимков первого уровня. Также появилась возможность настраивать размер блока (grain size) в SEsparse для соответствия типу используемого хранилища.
SEsparse по умолчанию применяется к VMDK объёмом более 2 ТБ на VMFS5, начиная с vSphere 7 Update 2. В vSphere 9 SEsparse становится форматом по умолчанию для всех VMDK на NFS и VMFS-5, независимо от размера. Это уменьшит задержки и увеличит пропускную способность чтения при работе со снимками. Формат SEsparse теперь также будет использоваться с NFS, если не используется VAAI snapshot offload plugin.
Поддержка спецификации vNVMe 1.4 — команда Write Zeroes
С выходом версии 9.0 поддержка NVMe 1.4 в виртуальном NVMe (vNVMe) позволяет гостевой ОС использовать команду NVMe Write Zeroes — она устанавливает заданный диапазон логических блоков в ноль. Эта команда аналогична SCSI WRITE_SAME, но ограничена только установкой значений в ноль.
Поддержка нескольких соединений на сессию iSCSI (Multiple Connections per Session)
Рекомендуется использовать iSCSI с Multi-path I/O (MPIO) для отказоустойчивого подключения к хостам. Это требует отдельных физических путей для каждого порта VMkernel и отказа от использования failover на базе состояния соединения или агрегацию сетевых интерфейсов (NIC teaming) или Link Aggregation Group (LAG), поскольку такие методы не обеспечивают детерминированный выбор пути.
Проблема: iSCSI традиционно использует одиночное соединение, что делает невозможным распределение трафика при использовании NIC teaming или LAG.
Решение — iSCSI с несколькими соединениями в рамках одной сессии, что позволяет:
Использовать несколько каналов, если один порт VMkernel работает в составе LAG с продвинутыми алгоритмами хеширования.
Повысить пропускную способность, когда скорость сети превышает возможности массива обрабатывать TCP через один поток соединения.
Важно: проконсультируйтесь с производителем хранилища, поддерживает ли он такую конфигурацию.
Выведенные из эксплуатации технологии
Устаревание NPIV
Как VMware предупреждала ранее, технология N-Port ID Virtualization (NPIV) была признана устаревшей и в версии 9.0 больше не поддерживается.
Устаревание гибридной конфигурации в оригинальной архитектуре хранения vSAN (OSA)
Гибридная конфигурация в vSAN Original Storage Architecture будет удалена в одном из будущих выпусков платформы VCF.
Устаревание поддержки vSAN over RDMA
Поддержка vSAN поверх RDMA для архитектуры vSAN OSA также будет прекращена в будущем выпуске VCF.
Устаревание поддержки RVC и зависимых Ruby-компонентов
Начиная с версии VCF 9.0, Ruby vSphere Console (RVC) и её компоненты на базе Ruby (такие как Rbvmomi) в составе vCenter считаются устаревшими. RVC, ранее использовавшаяся технической поддержкой для тестирования и мониторинга систем, уже была признана устаревшей, начиная с vSAN 7.0.
Для задач мониторинга и сопровождения Broadcom рекомендует использовать PowerCLI, DCLI или веб-интерфейс vCenter (UI), поскольку они теперь предоставляют весь функционал, ранее доступный в RVC. RVC и все связанные с ней Ruby-компоненты будут окончательно удалены в одном из будущих выпусков VCF.
В предыдущей статье мы рассмотрели, что производительность vSAN зависит не только от физической пропускной способности сети, соединяющей хосты vSAN, но и от архитектуры самого решения. При использовании vSAN ESA более высокоскоростные сети в сочетании с эффективным сетевым дизайном позволяют рабочим нагрузкам в полной мере использовать возможности современного серверного оборудования. Стремясь обеспечить наилучшие сетевые условия для вашей среды vSAN, вы, возможно, задаётесь вопросом: можно ли ещё как-то улучшить производительность vSAN за счёт сети? В этом посте мы обсудим использование vSAN поверх RDMA и разберёмся, подойдёт ли это решение вам и вашей инфраструктуре.
Обзор vSAN поверх RDMA
vSAN использует IP-сети на базе Ethernet для обмена данными между хостами. Ethernet-кадры (уровень 2) представляют собой логический транспортный слой, обеспечивающий TCP-соединение между хостами и передачу соответствующих данных. Полезная нагрузка vSAN размещается внутри этих пакетов так же, как и другие типы данных. На протяжении многих лет TCP поверх Ethernet обеспечивал исключительно надёжный и стабильный способ сетевого взаимодействия для широкого спектра типов трафика. Его надёжность не имеет аналогов — он может функционировать даже в условиях крайне неудачного проектирования сети и плохой связности.
Однако такая гибкость и надёжность имеют свою цену. Дополнительные уровни логики, используемые для подтверждения получения пакетов, повторной передачи потерянных данных и обработки нестабильных соединений, создают дополнительную нагрузку на ресурсы и увеличивают вариативность доставки пакетов по сравнению с протоколами без потерь, такими как Fibre Channel. Это может снижать пропускную способность и увеличивать задержки — особенно в плохо спроектированных сетях. В правильно организованных средах это влияние, как правило, незначительно.
Чтобы компенсировать особенности TCP-сетей на базе Ethernet, можно использовать vSAN поверх RDMA через конвергентный Ethernet (в частности, RoCE v2). Эта технология всё ещё использует Ethernet, но избавляется от части избыточной сложности TCP, переносит сетевые операции с CPU на аппаратный уровень и обеспечивает прямой доступ к памяти для процессов. Более простая сетевая модель высвобождает ресурсы CPU для гостевых рабочих нагрузок и снижает задержку при передаче данных. В случае с vSAN это улучшает не только абсолютную производительность, но и стабильность этой производительности.
RDMA можно включить в кластере vSAN через интерфейс vSphere Client, активировав соответствующую опцию в настройках кластера. Это предполагает, что вы уже выполнили все предварительные действия, необходимые для подготовки сетевых адаптеров хостов и коммутаторов к работе с RDMA. Обратитесь к документации производителей ваших NIC и коммутаторов для получения информации о необходимых шагах по активации RDMA.
Если в конфигурации RDMA возникает хотя бы одна проблема — например, один из хостов кластера теряет возможность связи по RDMA — весь кластер автоматически переключается обратно на TCP поверх Ethernet.
Рекомендация. Рассматривайте использование RDMA только в случае, если вы используете vSAN ESA. Хотя поддержка vSAN поверх RDMA появилась ещё в vSAN 7 U2, наибольшую пользу эта технология приносит в сочетании с высокой производительностью архитектуры ESA, начиная с vSAN 8 и выше.
Как указано в статье «Проектирование сети vSAN», использование RDMA с vSAN влечёт за собой дополнительные требования, ограничения и особенности. К ним относятся:
Коммутаторы должны быть совместимы с RDMA и настроены соответствующим образом (включая такие параметры, как DCB — Data Center Bridging и PFC — Priority Flow Control).
Размер кластера не должен превышать 32 хоста.
Поддерживаются только следующие политики объединения интерфейсов:
Route based on originating virtual port
Route based on source MAC hash
Использование LACP или IP Hash не поддерживается с RDMA.
Предпочтительно использовать отдельные порты сетевых адаптеров для RDMA, а не совмещать RDMA и TCP на одном uplink.
RDMA не совместим со следующими конфигурациями:
2-узловые кластеры (2-Node)
Растянутые кластеры (stretched clusters)
Совместное использование хранилища vSAN
Кластеры хранения vSAN (vSAN storage clusters)
В VCF 5.2 использование vSAN поверх RDMA не поддерживается. Эта возможность не интегрирована в процессы SDDC Manager, и не предусмотрено никаких способов настройки RDMA для кластеров vSAN. Любые попытки настроить RDMA через vCenter в рамках VCF 5.2 также не поддерживаются.
Прирост производительности при использовании vSAN поверх RDMA
При сравнении двух кластеров с одинаковым аппаратным обеспечением, vSAN с RDMA может показывать лучшую производительность по сравнению с vSAN, использующим TCP поверх Ethernet. В публикации Intel «Make the Move to 100GbE with RDMA on VMware vSAN with 4th Gen Intel Xeon Scalable Processors» были зафиксированы значительные улучшения производительности в зависимости от условий среды.
Рекомендация: используйте RDTBench для тестирования соединений RDMA и TCP между хостами. Это также отличный инструмент для проверки конфигурации перед развёртыванием производительного кластера в продакшене.
Fibre Channel — действительно ли это «золотой стандарт»?
Fibre Channel заслуженно считается надёжным решением в глазах администраторов хранилищ. Протокол Fibre Channel изначально разрабатывался с одной целью — передача трафика хранения данных. Он использует «тонкий стек» (thin stack), специально созданный для обеспечения стабильной и низколатентной передачи данных. Детеминированная сеть на базе Fibre Channel работает как единый механизм, где все компоненты заранее определены и согласованы.
Однако Fibre Channel и другие протоколы, рассчитанные на сети без потерь, тоже имеют свою цену — как в прямом, так и в переносном смысле. Это дорогая технология, и её внедрение часто «съедает» большую часть бюджета, уменьшая возможности инвестирования в другие сетевые направления. Кроме того, инфраструктуры на Fibre Channel менее гибкие по сравнению с Ethernet, особенно при необходимости поддержки разнообразных топологий.
Хотя Fibre Channel изначально ориентирован на физическую передачу данных без потерь, сбои в сети могут привести к непредвиденным последствиям. В спецификации 32GFC был добавлен механизм FEC (Forward Error Correction) для борьбы с кратковременными сбоями, но по мере роста масштаба фабрики растёт и её сложность, что делает реализацию сети без потерь всё более трудной задачей.
Преимущество Fibre Channel — не в абсолютной скорости, а в предсказуемости передачи данных от точки к точке. Как видно из сравнения, даже с учётом примерно 10% накладных расходов при передаче трафика vSAN через TCP поверх Ethernet, стандартный Ethernet легко может соответствовать или даже превосходить Fibre Channel по пропускной способности.
Обратите внимание, что такие обозначения, как «32GFC» и Ethernet 25 GbE, являются коммерческими названиями, а не точным отражением фактической пропускной способности. Каждый стандарт использует завышенную скорость передачи на уровне символов (baud rate), чтобы компенсировать накладные расходы протокола. В случае с Ethernet фактическая пропускная способность зависит от типа передаваемого трафика. Стандарт 40 GbE не упоминается, так как с 2017 года он считается в значительной степени устаревшим.
Тем временем Ethernet переживает новый виток развития благодаря инфраструктурам, ориентированным на AI, которым требуется высокая производительность без уязвимости традиционных «безубыточных» сетей. Ethernet изначально проектировался с учётом практических реалий дата-центров, где неизбежны изменения в условиях эксплуатации и отказы оборудования.
Благодаря доступным ценам на оборудование 100 GbE и появлению 400 GbE (а также приближению 800 GbE) Ethernet становится чрезвычайно привлекательным решением. Даже традиционные поставщики систем хранения данных в последнее время отмечают, что всё больше клиентов, ранее серьёзно инвестировавших в Fibre Channel, теперь рассматривают Ethernet как основу своей следующей сетевой архитектуры хранения. Объявление Broadcom о выпуске чипа Tomahawk 6, обеспечивающего 102,4 Тбит/с внутри одного кристалла, — яркий индикатор того, что будущее высокопроизводительных сетей связано с Ethernet.
С vSAN ESA большинство издержек TCP поверх Ethernet можно компенсировать за счёт грамотной архитектуры — без переподписки и с использованием сетевого оборудования, поддерживающего высокую пропускную способность. Это подтверждается в статье «vSAN ESA превосходит по производительности топовое хранилище у крупной финансовой компании», где vSAN ESA с TCP по Ethernet с лёгкостью обошёл по скорости систему хранения, использующую Fibre Channel.
Насколько хорош TCP поверх Ethernet?
Если у вас качественно спроектированная сеть с высокой пропускной способностью и без переподписки, то vSAN на TCP поверх Ethernet будет достаточно хорош для большинства сценариев и является наилучшей отправной точкой для развёртывания новых кластеров vSAN. Эта рекомендация особенно актуальна для клиентов, использующих vSAN в составе VMware Cloud Foundation 5.2, где на данный момент не поддерживается RDMA.
Хотя RDMA может обеспечить более высокую производительность, его требования и ограничения могут не подойти для вашей среды. Тем не менее, можно добиться от vSAN такой производительности и стабильности, которая будет приближена к детерминированной модели Fibre Channel. Для этого нужно:
Грамотно спроектированная сеть. Хорошая архитектура Ethernet-сети обеспечит высокую пропускную способность и низкие задержки. Использование топологии spine-leaf без блокировки (non-blocking), которая обеспечивает линейную скорость передачи от хоста к хосту без переподписки, снижает потери пакетов и задержки. Также важно оптимально размещать хосты vSAN внутри кластера — это повышает сетевую эффективность и производительность.
Повышенная пропускная способность. Устаревшие коммутаторы должны быть выведены из эксплуатации — им больше нет места в современных ЦОДах. Использование сетевых адаптеров и коммутаторов с высокой пропускной способностью позволяет рабочим нагрузкам свободно передавать команды на чтение/запись и данные без узких мест. Ключ к стабильной передаче данных по Ethernet — исключить ситуации, при которых кадры или пакеты TCP нуждаются в повторной отправке из-за нехватки ресурсов или ненадёжных каналов.
Настройка NIC и коммутаторов. Сетевые адаптеры и коммутаторы часто имеют настройки по умолчанию, которые не оптимизированы для высокой производительности. Это может быть подходящим шагом, если вы хотите улучшить производительность без использования RDMA, и уже реализовали два предыдущих пункта. В документе «Рекомендации по производительности для VMware vSphere 8.0 U1» приведены примеры таких возможных настроек.
Дункан Эппинг рассказал о том, как можно убедиться, что ваши диски VMware vSAN зашифрованы.
Если у вас включена техника шифрования "vSAN Encryption – Data At Rest", то вы можете проверить, что действительно данные на этих дисках зашифрованы в разделе настроек vSAN в клиенте vSphere Client. Однако вы можете сделать это и на уровне хоста ESXi, выполнив команду:
esxcli vsan storage list
Как вы можете увидеть из вывода команды, для шифрования указан параметр Encryption: true.
Второй момент - вам надо убедиться, что служба управления ключами шифрования Key Management System доступна и работает как положено. Это вы можете увидеть в разделе vSAN Skyline Health клиента vSphere:
Дункан также обращает внимание, что если вы используете Native Key Server и получаете ошибку "not available on host", проверьте, опцию "Use key provider only with TPM". Если она включена, то вы должны иметь модуль TPM для корректной работы механизмов шифрования. Если у вас модуля такого нет - просто снимите эту галочку.
Недавно мы писали о программном доступе к спискам совместимости Broadcom Compatibility Guide (BCG), а на днях стало известно, что ключевой компонент платформы VMware Cloud Foundation 9 - платформа VMware vSphere 9 - уже присутствует в BCG, так что можно проверять свои серверы и хранилища на предмет совместимости с VMware ESXi 9.0 и VMware vSAN 9.0:
Кстати в списках совместимости с vVols не указан VMware ESXi 9, так как эта технология будет признана deprecated в следующей версии платформы (и окончательно перестанет поддерживаться в vSphere 9.1).
Имейте в виду, что список совместимости еще может поменяться к моменту финального релиза VMware vSphere 9, но ориентироваться на это для планирования закупок можно уже сейчас.
Компания VMware недавно выпустила обновленную версию средства для виртуализации и агрегации сетей NSX 4.2.2, которое предлагает множество новых функций, обеспечивая расширенные возможности виртуализованных сетей и безопасности для частных облаков.
Основные улучшения охватывают следующие направления:
Межсетевой экран vDefend представляет новый высокопроизводительный режим Turbo (SCRX), который повышает производительность распределённой IDS/IPS-системы и механизма обнаружения приложений уровня L7 для распределённого межсетевого экрана. Новый механизм инспекции использует детерминированное распределение ресурсов и расширенные конвейеры обработки пакетов в гипервизоре ESXi, обеспечивая прирост производительности при значительно меньшем потреблении ресурсов памяти и процессора.
Enhanced Data Path (EDP) получил ряд улучшений, включая добавление скрипта, снижающего необходимость ручного вмешательства при включении EDP в кластере, а также улучшения стабильности, совместимости и снижение влияния на операции жизненного цикла.
В этом выпуске VMware NSX включает улучшения платформы Edge, в том числе новую опцию повторного развертывания и улучшенную документацию по API мониторинга Edge.
Скрипт Certificate Analyzer Resolver (CARR) теперь поддерживает проверку сертификатов Compute Manager (vCenter). Он выполняет проверку целостности и восстановление самоподписных сертификатов NSX, а также может заменять сертификаты, срок действия которых истёк или скоро истечёт.
Среди новых улучшений безопасности платформы — предопределённая роль Cloud Admin Partner, увеличение числа поддерживаемых групп LDAP и Active Directory, а также поддержка стандарта FIPS 140-3.
Сетевые возможности
1. Сеть канального уровня (Layer 2 Networking)
Появился скрипт автоматизации включения режима коммутатора EDP для VCF 5.2.x (NSX 4.2.2). В состав NSX Manager добавлен скрипт enable_uens, предназначенный для сокращения ручных действий при включении режима Enhanced Data Path Standard на кластере. Скрипт последовательно выполняет следующие шаги на хостах:
Переводит хост в режим обслуживания
Обновляет режим коммутатора на EDP
Выводит хост из режима обслуживания
Синхронизирует изменения с Transport Node Profile кластера
Он выполняется из той же директории и применяется к одному кластеру за раз, требуя входных данных из JSON-файла. Подробные инструкции приведены в файле readme скрипта.
Скрипт особенно полезен для релизов NSX 4.x, так как смена режима передачи данных на EDP Standard через настройки Transport Node Profile вызывает немедленные изменения на хостах ESXi, что может привести к сетевому простою на несколько секунд на каждом хосте. Метод "Enabling EDP Standard in Active Environments" снижает простой, но требует ручного вмешательства на каждом хосте, что при масштабных развертываниях становится крайне трудоёмким из-за шагов с режимом обслуживания.
2. Повышение надёжности EDP Standard в рамках долгосрочной поддержки (LTS)
NSX 4.2.2 рекомендуется как основная версия для использования Enhanced Data Path во всех развертываниях VMware Cloud Foundation и типах рабочих доменов, включая кластеры NSX Edge и общие вычислительные кластеры (VI Workload Domains).
EDP рекомендован для достижения максимальной производительности обработки сетевого трафика и минимизации затрат ресурсов на сетевую обработку. В этом релизе реализованы улучшения стабильности и совместимости, благодаря чему он рекомендован в качестве версии с долгосрочной поддержкой (LTS) для NSX 4.2.
Основные улучшения надёжности в NSX 4.2.2:
Повышена производительность EDP при масштабных развертываниях.
Улучшена работа EDP в средах на базе vSAN.
Повышена производительность EDP при использовании распределённого межсетевого экрана.
Расширена совместимость с сетевыми адаптерами через механизм driver shimming.
Совместимость EDP с контейнерными платформами (NCP, Antrea).
Повышена доступность (uptime) канала данных EDP Standard при операциях жизненного цикла — время переключения сокращено с десятков секунд до менее чем 3 секунд.
В пользовательском интерфейсе добавлена кнопка Redeploy Edge, позволяющая легко и быстро повторно развернуть узел Edge. Эта операция запускает соответствующий API, как указано в документации: NSX Edge VM Redeploy API.
Это улучшение упрощает процесс повторного развертывания, снижает операционные издержки и улучшает пользовательский опыт, предоставляя возможность настройки параметров Edge при повторном запуске.
Обновлённая документация по API мониторинга NSX Edge теперь предоставляет более понятные и подробные инструкции. В ней содержатся:
Подробные объяснения всех соответствующих API-вызовов с примерами запросов и ответов.
Полные описания возвращаемых мониторинговых данных, включая поэлементную расшифровку каждого поля.
Глубокое разъяснение всех доступных метрик: что они обозначают, как рассчитываются и как их интерпретировать в реальных сценариях.
Безопасность
1. Межсетевой экран (Firewall)
Распределённый межсетевой экран (Distributed Firewall) использует новый высокопроизводительный режим Turbo (SCRX) для фильтрации приложений уровня L7.
NSX Manager теперь поддерживает большее количество сервисов межсетевого экрана для экземпляров класса Extra Large. Подробности см. в разделе Configuration Maximums.
Группировка в межсетевом экране поддерживает большее число активных участников как для конфигураций Large, так и Extra Large. Подробнее — в Configuration Maximums.
2. IDS/IPS
Распределённая система IDS/IPS демонстрирует значительный прирост производительности благодаря новому высокопроизводительному движку Turbo (SCRX). При использовании нового движка возможно достичь скорости анализа трафика до 9 Гбит/с в зависимости от профиля трафика на хосте ESXi.
Показатели производительности и другие операционные метрики Distributed IDS/IPS доступны в реальном времени через Security Services Platform (SSP).
Внимание: новый движок SCRX предъявляет строгие требования к совместимости с версией ESXi, а также имеет особые условия для установки/обновления. См. раздел Getting Started и выполните Turbo Mode Compatibility Pre-Check Script для проверки среды. Дополнительную информацию можно найти в базе знаний (KB) — статья 396277.
Настоятельно рекомендуется запускать скрипт CARR перед обновлением NSX Manager. Цель — убедиться, что срок действия сертификатов Transport Node (TN) не истекает в течение 825 дней. Если срок действия сертификата TN меньше этого значения, скрипт можно повторно запустить для его замены. См. статью Broadcom KB 369034.
2. Управление доступом (RBAC)
Добавлена новая предопределённая роль Cloud Partner Admin — специально для облачных партнёров, которым необходим доступ к функциям сетей и безопасности, но при этом нужно исключить доступ к просмотру лицензий NSX.
3. Аутентификация через LDAP
Увеличено максимальное число поддерживаемых групп LDAP и Active Directory — с 20 до 500.
4. Сертификация платформы
Поддержка стандарта FIPS 140-3: NSX 4.2.2 теперь использует криптографические модули, соответствующие требованиям FIPS 140-3 (Federal Information Processing Standards). NSX работает в режиме соответствия FIPS по умолчанию во всех развертываниях. Подтверждение соответствия стандарту FIPS 140-3 гарантирует, что NSX использует актуальные криптомодули для надёжной защиты рабочих нагрузок. Дополнительная информация о модулях доступна по ссылке в оригинальной документации.
Broadcom Compatibility Guide (ранее VMware Compatibility Guide) — это ресурс, где пользователи могут проверить совместимость оборудования (нового или уже используемого) с программным обеспечением VMware. Вильям Лам написал интересную статью о доступе к BCG через программный интерфейс VMware PowerCLI.
Существует несколько различных руководств по совместимости, которые можно использовать для поиска информации, начиная от процессоров и серверов и заканчивая разнообразными устройствами ввода-вывода, такими как ускорители и видеокарты. Если у вас небольшое количество оборудования, поиск будет достаточно простым. Однако, если необходимо проверить разнообразное оборудование, веб-интерфейс может оказаться не самым быстрым и удобным вариантом.
Хорошая новость в том, что Broadcom Compatibility Guide (BCG) может легко использоваться программно, в отличие от предыдущего VMware Compatibility Guide (VCG), у которого была другая система бэкенда.
Хотя официального API с документацией, поддержкой и обратной совместимостью для BCG нет, пользователи могут взаимодействовать с BCG, используя тот же API, который применяется веб-интерфейсом BCG.
Обе функции предполагают поиск на основе комбинации идентификаторов поставщика (Vendor ID, VID), идентификатора устройства (Device ID, DID) и идентификатора поставщика подсистемы (SubSystem Vendor ID, SVID).
Примечание: BCG предоставляет разнообразные возможности поиска и фильтрации; ниже приведены лишь примеры одного из способов работы с API BCG. Если вам интересны другие методы поиска, ознакомьтесь со справочной информацией в конце документа, где описаны иные опции фильтрации и руководства по совместимости BCG.
Шаг 1 – Загрузите скрипт queryHostPCIInfo.ps1 (который Вильям также обновил, чтобы можно было легко исключить неприменимые устройства с помощью строк исключений), и запишите идентификаторы устройств (VID, DID, SVID), которые вы хотите проверить.
По умолчанию функция возвращает четыре последние поддерживаемые версии ESXi, однако вы можете изменить это, указав параметр ShowNumberOfSupportedReleases:
При проверке SSD-накопителей vSAN через BCG вы также можете указать конкретный поддерживаемый уровень vSAN (Hybrid Cache, All-Flash Cache, All-Flash Capacity или ESA), используя следующие параметры:
Если вы хотите автоматизировать работу с другими руководствами по совместимости в рамках BCG, вы можете определить формат запроса (payload), используя режим разработчика в браузере. Например, в браузере Chrome, перед выполнением поиска в конкретном руководстве по совместимости, нажмите на три точки в правом верхнем углу браузера и выберите "More Tools->Developer Tools", после чего откроется консоль разработчика Chrome. Далее вы можете использовать скриншот, чтобы разобраться, как выглядит JSON-запрос для вызова API "viewResults".
1. Увеличение минимального объёма лицензии к закупке до 72 ядер и откат обратно к 16
Broadcom продолжает переход на модель подписки для продуктов VMware (не все крупные копании еще перешли на эту модель). Также теперь лицензии предоставляются на основе количества ядер процессора, а не сокетов сервера. При этом минимальный объём лицензии на продукт VMware vSphere Foundation (VVF) недавно должен был быть увеличен с 16 до 72 ядер (то есть минимальный объем заказа). Это означало бы, что даже если у клиента, например, 3 односокетных сервера с 16 ядрами в каждом процессоре, он был бы вынужден приобрести лицензию на 72 ядра, а не 48 как раньше (минимально можно было купить лицензию на 16 ядер на каждый из сокетов серверов). Для небольших компаний и удалённых офисов это привело бы к значительному увеличению затрат.
Напомним основные правила лицензирования VMware vSphere Foundation, которые продолжают действовать:
1. Минимальный объем лицензий на один сокет сервера - 16 ядер.
2. Если на каждом сервере 2 сокета по 12 ядер (24 ядра на сервер) и таких серверов у вас 3, то нужно будет 6 лицензий на 16 ядер каждая (то есть, 96).
3. Если у вас в процессорах серверов более 16 ядер, то вам нужно число процессоров просто умножить на число ядер, чтобы получить необходимое количество лицензий.
4. Если у вас, например, лицензированы 10 односокетных хостов, и вы заменили 16-ядерные CPU на 24 ядерные, то вам нужно докупить (24-16)*10=80 лицензий.
После объявления о повышении минимального количества ядер до 72, Broadcom столкнулась с критикой со стороны клиентов и партнёров. Многие выражали обеспокоенность тем, что это изменение негативно скажется на малом и среднем бизнесе. В результате компания то ли отменила это решение, то ли его и не было (см. комментарии) и сохранила прежний минимум в 16 ядер (в Broadcom отрицают, что вообще анонсировали это). Но мы еще подождем официальных анонсов на эту тему.
2. Штраф за просрочку продления лицензии
Теперь за несвоевременное продление лицензии предусмотрен штраф в размере 20% от стоимости первого года подписки. Этот штраф применяется ретроспективно, что может привести к неожиданным дополнительным расходам для клиентов.
Партнёры и клиенты выражают обеспокоенность новыми условиями. Многие рассматривают альтернативы, такие как Microsoft Hyper-V, Proxmox и Scale Computing, особенно для небольших и средних предприятий. Партнёры VMware отмечают, что новые условия могут оттолкнуть клиентов с небольшими инфраструктурами, которые ранее были основой клиентской базы VMware.
Кстати, смотрите, как выглядит сайт Scale Computing:
Начиная с ноября 2024 года, VMware vSphere Foundation (VVF) начала включать 0,25 ТиБ ёмкости vSAN на одно ядро для всех новых лицензий VVF. С выходом обновления vSphere 8.0 U3e это преимущество распространяется и на существующих клиентов — теперь им также доступна ёмкость vSAN из расчёта 0,25 ТиБ (аналог терабайта) на ядро. Это новое право на использование включает дополнительные преимущества, которые повышают ценность vSAN в составе VVF.
Вот как это работает:
Ёмкость vSAN агрегируется по всей инфраструктуре, что позволяет перераспределять неиспользованные ресурсы с кластеров, содержащих только вычислительные узлы, на кластеры с включённым vSAN. Это помогает оптимизировать использование ресурсов в рамках всей инфраструктуры.
Новые преимущества для текущих клиентов:
Больше никаких ограничений пробной версии: включённые 0,25 ТиБ на ядро теперь полностью предоставлены по лицензии, а не в рамках пробного периода.
Агрегация ёмкости: объединяйте хранилище между кластерами и используйте его там, где это нужнее всего.
Упрощённое масштабирование: если требуется больше хранилища, чем предусмотрено по включённой норме — достаточно просто докупить нужный объём сверх этой квоты.
Почему это важно
Благодаря этому обновлению VMware vSphere Foundation становится ещё более привлекательным решением для организаций, стремящихся модернизировать и унифицировать свою ИТ-инфраструктуру. Поддерживая как виртуальные машины, так и контейнеры, vSAN добавляет возможности гиперконвергентной инфраструктуры (HCI) корпоративного уровня. Интеграция вычислений, хранения и управления в единую платформу упрощает операционные процессы, снижает сложность и обеспечивает комплексное решение с встроенной безопасностью и масштабируемостью.
Дополнительная ёмкость vSAN в составе VMware vSphere Foundation значительно повышает ценность платформы — будь то оптимизация частного облака, повышение гибкости разработки или упрощение ИТ-операций. Это даёт больше контроля и гибкости над инфраструктурой, снижая совокупную стоимость владения и минимизируя операционные издержки.
Чтобы начать пользоваться бесплатной лицензией VMware vSAN загрузите патч vSphere 8.0 Update 3e по этой ссылке.
Intel недавно представила новое поколение серверных процессоров — Intel Xeon 6 с производительными ядрами (Performance-cores), которые отличаются увеличенным числом ядер и более высокой пропускной способностью памяти. Чтобы продемонстрировать производительность и масштабируемость этих процессоров, VMware опубликовала новые результаты тестов VMmark 4, полученных при участии двух ключевых партнёров — Dell Technologies и Hewlett Packard Enterprise. Конфигурация Dell представляет собой пару узлов в режиме «Matched Pair», а результат HPE получен на четырёхузловом кластере VMware vSAN. Оба результата основаны на VMware ESXi 8.0 Update 3e — первой версии, поддерживающей эти процессоры. Новые данные уже доступны на странице результатов VMmark 4.
Сравнение производительности: «Granite Rapids» и «Emerald Rapids»
В качестве примера, иллюстрирующего высокую производительность и масштабируемость, ниже приводится таблица с двумя результатами VMmark 4, позволяющая сравнить процессоры предыдущего поколения “Emerald Rapids” с новыми “Granite Rapids” серии 6700.
В последнее время в индустрии виртуализации наблюдалась тревожная тенденция — крупнейшие игроки начали отказываться от бесплатных версий своих гипервизоров. После покупки VMware компанией Broadcom одной из первых резонансных новостей стало прекращение распространения бесплатного гипервизора VMware ESXi (ранее известного как vSphere Hypervisor). Это решение вызвало волну недовольства в сообществе, особенно среди ИТ-специалистов и малых компаний, использующих ESXi в тестовых или домашних лабораториях.
Ранее: Broadcom, завершив поглощение VMware, прекратила предоставление бесплатной версии vSphere Hypervisor. Это вызвало резкую критику и обеспокоенность среди пользователей, привыкших использовать ESXi в учебных, тестовых или малобюджетных инфраструктурах.
Теперь: В составе релиза ESXi 8.0 Update 3e появилась entry-level редакция гипервизора, которая предоставляется бесплатно, как указано в разделе "What's New" официальной документации Broadcom. Хотя точных технических ограничений этой редакции пока не раскрыто в деталях, уже ясно, что она рассчитана на начальный уровень использования и доступна без подписки.
Почему это важно?
Возвращение бесплатной версии гипервизора от Broadcom означает, что:
Независимые администраторы и энтузиасты снова могут использовать ESXi в личных или образовательных целях.
Организации с ограниченным бюджетом могут рассматривать VMware как вариант для пилотных проектов.
Broadcom, вероятно, отреагировала на давление сообщества и рынка.
Новые возможности VMware 8.0 Update 3e:
1. Поддержка протокола CDC-NCM (Communication Device Class Network Control Model) в USB-драйвере ESXi
Начиная с версии ESXi 8.0 Update 3e, USB-драйвер ESXi поддерживает протокол CDC-NCM для обеспечения совместимости с виртуальным сетевым адаптером HPE Gen12 iLO (iLO Virtual NIC) и взаимодействия с такими инструментами, как HPE Agentless Management (AMS), Integrated Smart Update Tools (iSUT), iLORest (инструмент настройки), Intelligent Provisioning, а также DPU.
2. ESXi 8.0 Update 3e добавляет поддержку технологии vSphere Quick Boot для следующих драйверов:
Intel vRAN Baseband Driver
Intel Platform Monitoring Technology Driver
Intel Data Center Graphics Driver
Драйвер серии AMD Instinct MI
Вывод
Хотя отказ от бесплатной версии ESXi вызвал разочарование и обеспокоенность, возвращение entry-level редакции в составе ESXi 8.0 Update 3e — это шаг в сторону компромисса. Broadcom, похоже, услышала голос сообщества и нашла способ вернуть гипервизор в открытый доступ, пусть и с оговорками. Теперь остаётся дождаться подробностей о лицензировании и технических возможностях этой редакции.

 RSS
RSS